Balancing Cost and Performance on Google Cloud Run

Since 2018, Google’s Cloud Run service has transformed how developers deploy containerized applications by offering a serverless platform that fully manages underlying infrastructure management. With its ability to run stateless containers in a fully managed environment, Cloud Run provides scalability and flexibility, all together with a pay-per-use pricing model. This makes it a powerful choice for applications of all sizes.
“With great power comes great responsibility.”
As applications scale and become increasingly complex, managing costs can present challenges. Issues like over-provisioning resources and misconfigured settings can lead to unexpected expenses. It’s our responsibility as developers to ensure that we strike the perfect balance of cost, efficiency, and availability to maximize the benefits of Cloud Run without overspending.
In part one of this blog post, we'll dive into configuring Cloud Run instances by understanding how to fine-tune your services for efficiency and exploring the key cost drivers. This will help us find the “sweet spot” between performance and cost.
Configuring Resources Purposefully
When developing a project for the first time in rather scrappy fashion, we begin with the default bare minimum settings until we run into performance bottlenecks. In practice, we’ll configure slight adjustments to the CPU and memory, re-deploy the app, and see how the system responds. This iterative yet informal process actually lays the groundwork for more structured optimization efforts later on, mirroring the principles of profiling and benchmarking.
To determine the optimal settings for your application use case, we recommend load testing to benchmark their resource requirements. Going through this critical exercise will ensure that you know the ins-and-outs of your application and under which load and concurrency conditions it should remain stable.
We at SZNS Solutions use a combination of Locust, Apache JMeter, and Google Cloud Monitoring to conduct our load tests and metrics gathering. While this blog will not go in-depth into load testing, some general advice is to start iteratively with realistic traffic patterns and data volumes that mirror your production environment, as simplified test data may not reveal memory leaks or performance bottlenecks that only emerge under real-world conditions. For meaningful results, ensure your tests run for sufficient duration to account for both cold starts and steady-state performance.
Through our experience, we've found that targeting a CPU and memory utilization range of 50-70% is ideal—this range indicates efficient resource usage while maintaining enough headroom to handle unexpected spikes in demand. Going above this range risks performance and out-of-memory errors, while running significantly below suggests you're paying for unused resources.
Right-sizing your configurations for optimal performance and efficiency will avoid the common pitfall of over-provisioning more CPU and memory than your application actually requires.
Common Configurations and their Effects on Cost
In serverless computing, we often need to balance the trade-offs between performance and cost. Once we understand how to configure our services adequately, we can fully comprehend how tuning them affect costs.
In a nutshell, Cloud Run charges based on the CPU and memory allocated to your service per instance, multiplied by the time the instance is active. The time the instance is active is determined by whether or not the instance is actively serving a request.
Cloud Run offers two CPU allocation modes, which results in a slight variation in the pricing model.
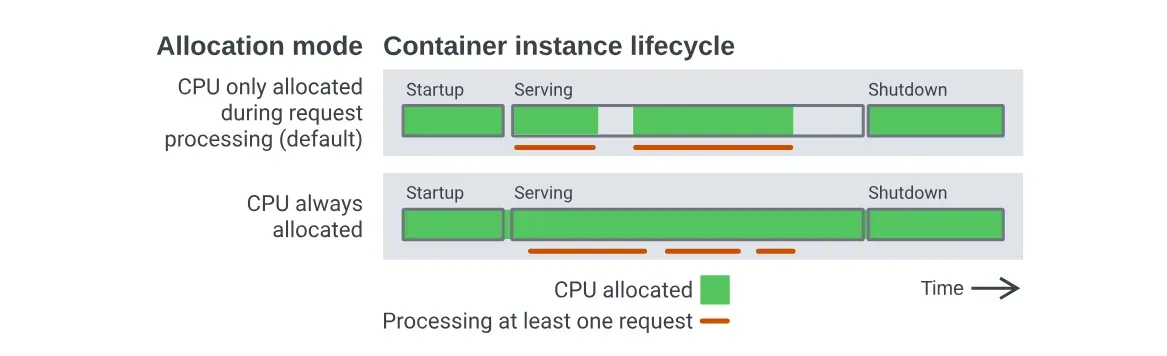
CPU Always-Allocated
CPU is allocated even when instances are not processing requests. It costs $0 for requests and comes at a cheaper rate compared to on-demand pricing (CPU is priced 25% lower and memory 20% lower).
CPU Allocated on Demand
CPU is allocated only when the instance is processing a request. It costs $0.40 / 1 million requests (not including free tier quota) and comes at a higher rate compared to always-allocated pricing.
-23f69c.webp)
Comparison
At face value, it may seem that always-allocated CPU is the cheaper option because there is no request cost and has a cheaper rate. When comparing a day’s worth of instance active time against both CPU allocation modes, on-demand is significantly more expensive.
In actuality, the cheapest option largely depends on how your application is used. While always-allocated pricing offers lower rates and no charge for requests, you’ll pay for more time since the CPU is always active, keeping the instance running continuously. Conversely, on-demand pricing may have a higher cost per second, but it can be more affordable overall if your application isn’t used continuously.
Ultimately, the best choice varies from one application to another and should be decided based on your application’s specific usage patterns.
Always-Allocated CPU: Applications requiring background processing between requests. Combined with minimum instances, can enable streaming use cases. Can be more cost-efficient for consistent traffic as there is less startup time between servicing requests.
On-Demand CPU: Stateless applications that only need CPU during request processing. Ideal for applications that can tolerate some latency and for sporadic workloads. Can be more cost-effective for applications without background tasks.
If you’re still not sure, you can start with the default on-demand settings and adjust as you go. Another helpful inclusion at play is Google's Recommender, which automatically analyzes your Cloud Run service's traffic over the past month and will suggest switching to always-allocated CPU if it proves to be a more cost-effective option.
Autoscaling
Cloud Run's built-in autoscaling offers powerful tools for balancing capacity and cost, but effective use requires thoughtful configuration.
Cloud Run typically scales down to zero instances when a revision isn’t receiving traffic. However, you can adjust this behavior by specifying a minimum number of instances to remain idle, also known as "warm" instances. For applications that rely on CPU resources even outside of handling requests, it’s recommended to set the minimum instances to at least 1, ensuring that there's always at least one active instance.
-48507c.webp)
-d87a64.webp)
Scaling decisions are influenced by several factors: the average CPU usage over a 1-minute period (targeting 60% utilization per instance), the current request concurrency relative to the maximum allowed over that same timeframe, and the configured limits for minimum and maximum instances.
Since instances using always-allocated CPU never drop to 0% usage, relying solely on CPU activity would prevent scaling to zero. Instead, Cloud Run determines whether to scale an instance down to zero based on whether it’s actively processing requests. If there are no active requests, the service can scale down to zero despite the baseline CPU allocation. By default, instances will not remain idle for more than 15 minutes after processing a request unless minimum instances are explicitly set to keep them active.
Similarly, it's important to set appropriate maximum instance limits to avoid uncontrolled scaling and unexpected costs during traffic surges.

In addition, to handle sudden traffic spikes, you can implement complementary strategies such as request queuing or rate limiting. These techniques help manage burst traffic effectively, reducing the need for excessive instance scaling and offering a more cost-efficient way to maintain service stability under fluctuating workloads.
Concurrency Settings
Concurrency controls how many requests an instance can handle simultaneously. Cloud Run offers a setting to define the maximum number of concurrent requests an instance can handle, allowing you to control how many requests are processed simultaneously by a single instance.
-89c753.webp)
Setting limits too low can cause Cloud Run to spin up more instances than necessary, leading to higher costs due to increased resource usage. This indicates that your container is not able to process many concurrent requests. On the other hand, setting limits too high can result in performance bottlenecks if each request requires more resources to handle the workload.
-6a51a2.webp)
Inefficient concurrency settings can lead to underutilized instances or overloaded ones, affecting both performance and cost.
| Use Case | Benefit | |
|---|---|---|
| Increase Concurrency | Applications that are I/O-bound or have low CPU utilization per request. Think lightweight tasks like data aggregation. | Higher concurrency can reduce the number of instances needed, lowering costs. |
| Decrease Concurrency (Or Concurrency of 1) | CPU-intensive applications or those that cannot handle multiple requests at once. Relies on a global state that two requests cannot share. | Ensures optimal performance per request but may increase the number of instances and cost. |
Committed Use Discounts
Lastly, one feature not related to configuration that can help lower costs based on knowledge of how your application works is Cloud Run’s spend-based Committed Use Discount (CUD). Many workloads, such as websites or APIs with steady traffic patterns, generate predictable costs. For such use cases, CUDs provide a practical solution for cost control.
With CUDs, you can commit to a fixed spend amount for one year and receive a 17% discount on that commitment. This discount automatically applies to all aggregated Cloud Run usage (CPU, memory, and requests) in a region, across all projects within your billing account.
For example, if your Cloud Run services in a specific region consistently cost $1 per hour, committing to spend $1 per hour for a year reduces your hourly charge to $0.83.
By leveraging committed use discounts, you can optimize your Cloud Run spend, maintain predictable costs, and maximize savings without compromising performance or scalability.
Conclusion
That's all for now! So far we've explored how balancing costs and efficiency in Google Cloud Run requires a thoughtful approach to service configuration and an understanding of your application's usage patterns.
With everything covered here, we encourage you to assess your own Cloud Run setups. Have you load tested and profiled your application to configure its resources purposefully? Are your CPU and memory configurations aligned with actual usage? Are your concurrency and autoscaling settings supporting your application's realistic and worst-case scenarios?
As a sneak peak, in our next blog post, we’ll continue on this topic and tie our learnings together to share how we used all these configurations, as well as a customized automated scaling strategy within GCP to reduce our client's cloud bill significantly.
In the meantime, our team at SZNS is passionate about helping others with our expertise. If there’s something you need assistance with, we’re just a message away!
References
Load Testing Explained
Tools

Cloud Run Configuration
CPU Allocation Modes Explained
Autoscaling: Set maximum number of instances
Autoscaling: Set minimum number of instances
Concurrency: Set maximum concurrent requests


