Balancing Cost and Performance on Google Cloud Run: A Client Story

Today we’ll share a real-world client story that motivated our previous blog post and how our custom automated scaling solution led to significant cost savings during off-peak hours.
Bringing together everything we've learned about balancing Cloud Run costs and performance stems from a real-world issue faced by one of our clients. They were dealing with unexpectedly high Cloud Run costs, primarily due to over-provisioned instances. This was particularly evident on weekends when user demand dropped significantly, leaving idle instances running and driving up unnecessary expenses.
Analyzing the Problem
Our team's analysis revealed that their Cloud Run services were configured with a high minimum instance count combined with always-allocated CPUs, originally implemented to maintain low latency during weekday peak hours. However, after examining traffic patterns, we discovered a substantial drop in user activity during weekends. This mismatch between capacity and demand meant that idle instances were consuming resources—and therefore costs—during these low-traffic periods without corresponding user activity to justify the expense.
The Solution
Since the weekday activity on the services required minimum instances and configurations that mitigated cold start issues and high-latency response times, we couldn't simply rely on Cloud Run's native autoscaling behavior. We needed a solution where we could define the minimum and maximum scaling thresholds to support production workloads based on predicted user patterns.
To address this, we implemented an automated scaling strategy using Cloud Scheduler and Cloud Functions. While we considered a more aggressive cost-saving approach of completely shutting down services during weekends using Terraform, we ultimately opted for a more balanced solution. In other words, while a complete shutdown would have maximized cost savings, it would have resulted in either complete service unavailability or significantly longer cold starts when services needed to be spun up on demand for the occasional weekend workload.
Our automated scaling approach struck an optimal balance between cost optimization and service availability, maintaining reasonable response times for weekend users while still achieving substantial cost reductions through reduced resource allocation.
Solution Architecture
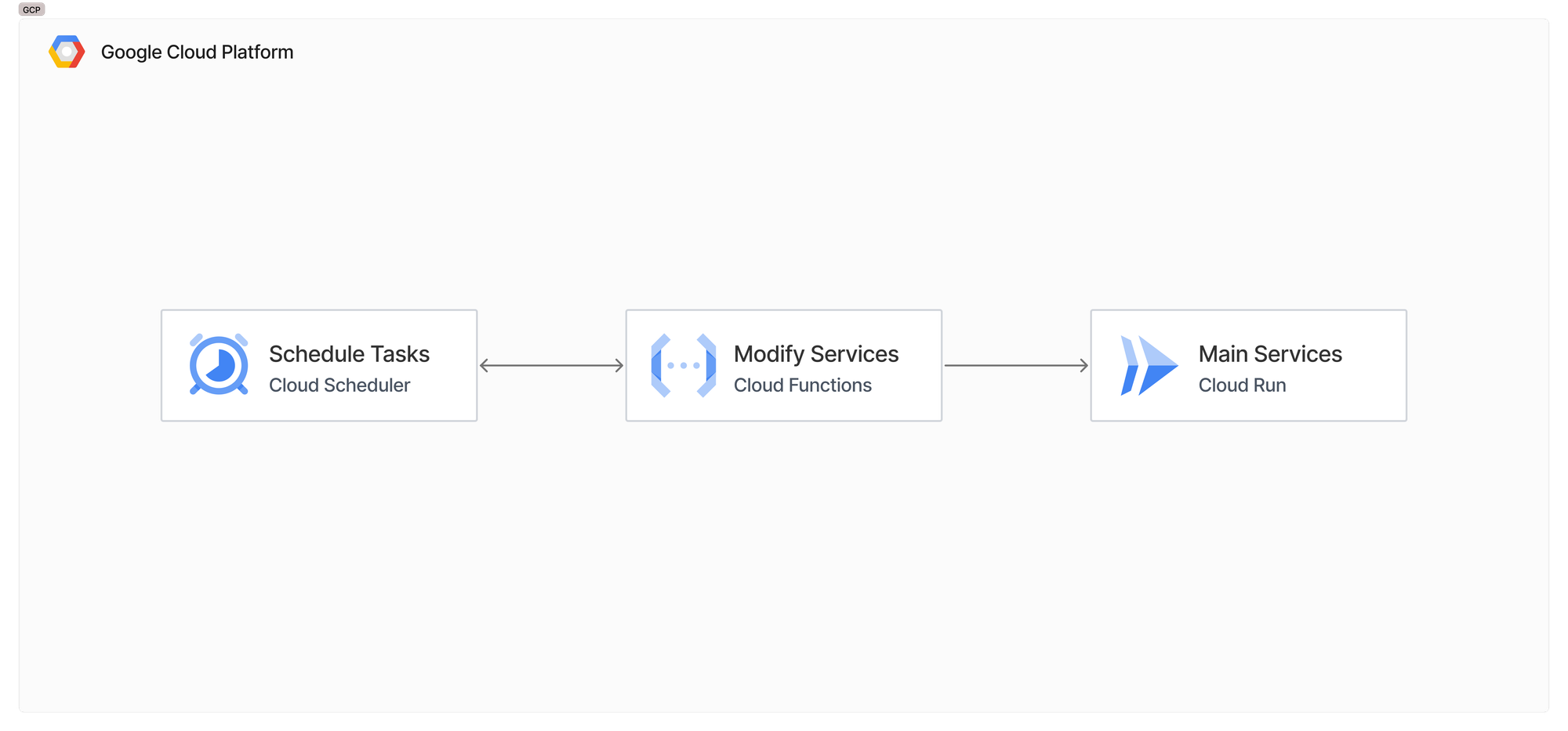
In our proposed solution, the Cloud Functions interact with the Cloud Run API to modify the service configurations programmatically. Cloud Scheduler sets up the scheduled tasks to adjust the Cloud Run service settings at specific times.
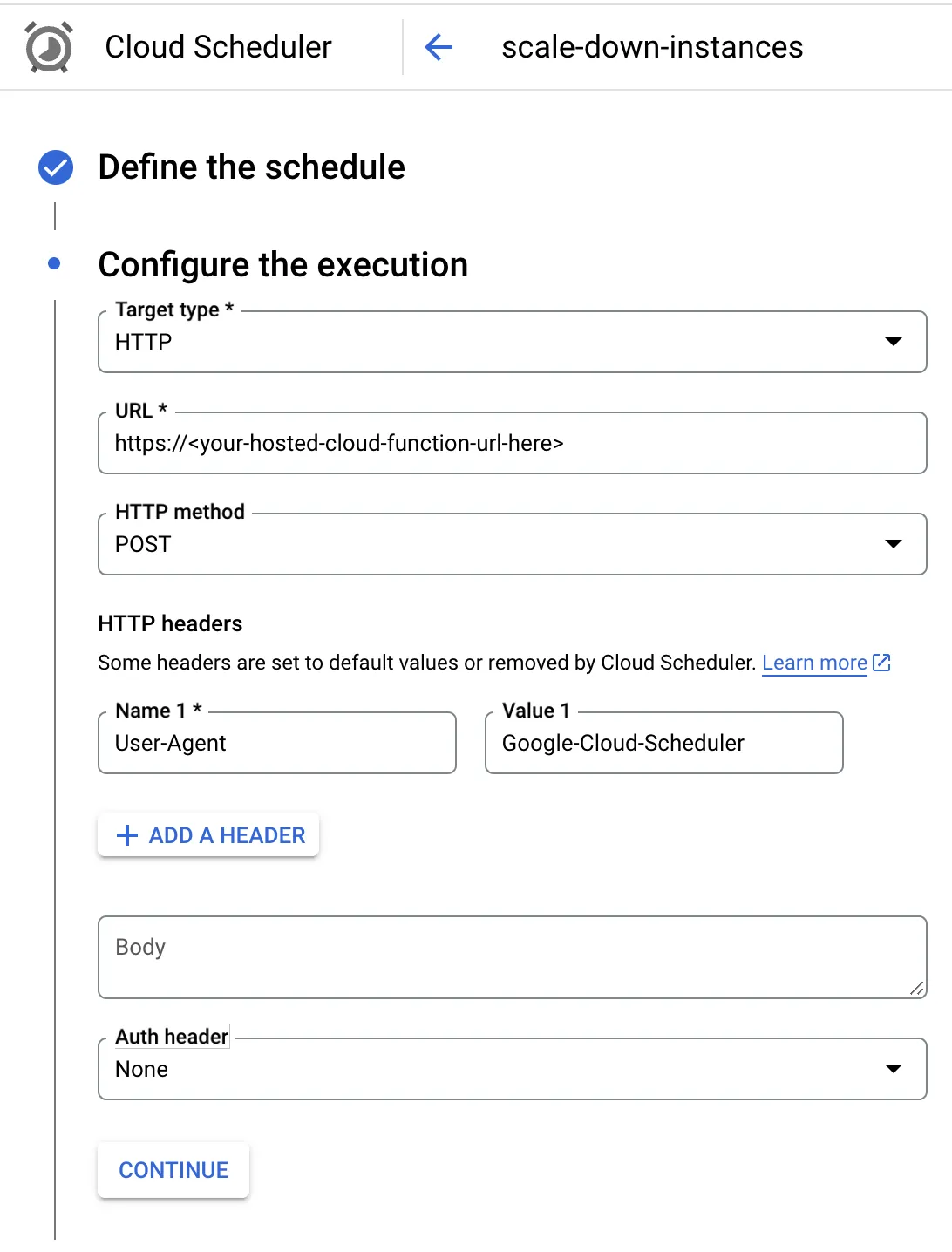
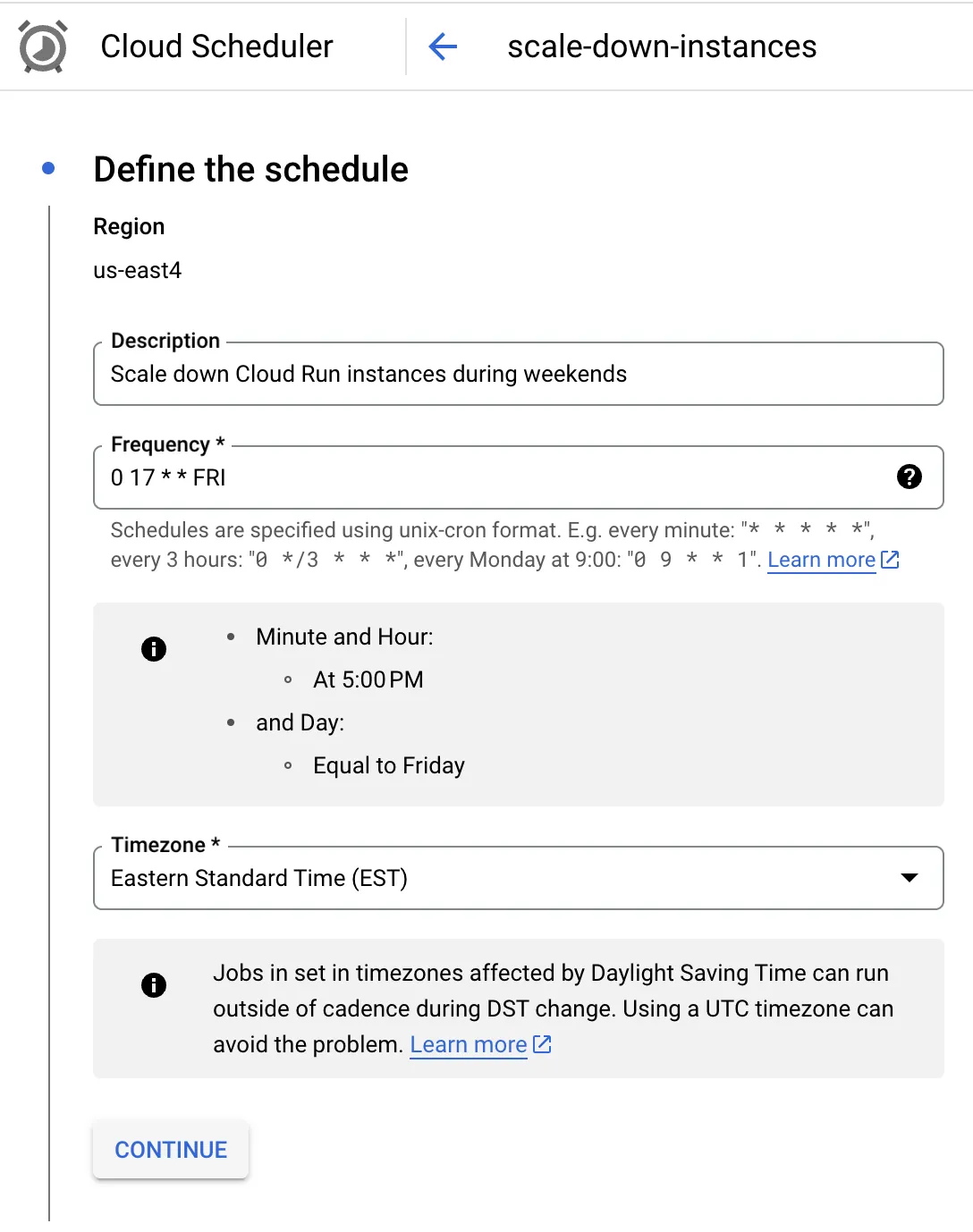
For our use case, we configured Cloud Scheduler to trigger our Cloud Function on Friday evening at 5 PM EST. The function then updates the Cloud Run services to reduce the minimum instance count and CPU allocation setting.
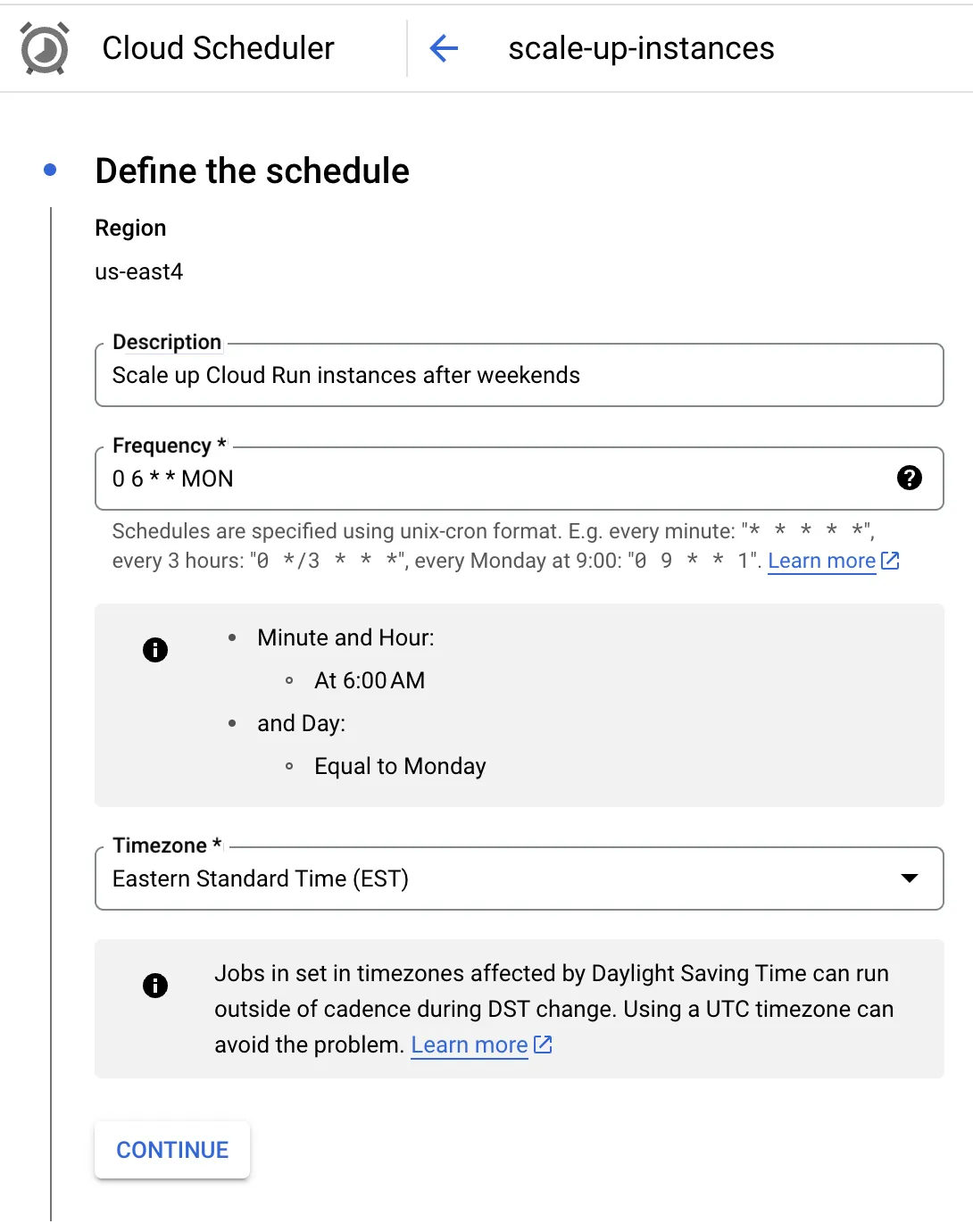
Then, on Monday morning, another scheduled task increases the minimum instance count and CPU allocation setting. This ensures the services are ready for peak weekday traffic to operate under normal business conditions.
Implementing the Solution
The Cloud Function has two environment variables that are leveraged, GCP_PROJECT which simply refers to your GCP project ID, and SERVICE_CONFIG which refers to a JSON string that has each service’s configuration.
{
"service-a": {
"region": "us-east4",
"minInstances": 10
},
"service-b": {
"region": "us-east4",
"minInstances": 20
},
"service-c": {
"region": "us-east4",
"minInstances": 5
},
"service-d": {
"region": "us-east4",
"minInstances": 3
}
}
Here we have already load tested and identified the minimum instances required to handle weekday production loads.
service-a through service-d should refer to the Cloud Run services you’re targeting for automatic scale-down/up. The minInstances setting will be used when scaling up to ensure that the desired minimum instances are set. You can remove or add the number of services as necessary.
Ensure that the Cloud Function has the Artifact Registry Reader and Cloud Run Admin roles on its service account to make the necessary changes while adhering to the principle of least privilege.
The example code below parses through the service config for each service present and scales down to 0 minimum instances and sets CPU allocation to on-demand. This is the main code included in our Cloud Function.
import os
import json
import functions_framework
from googleapiclient import discovery
import google.auth
import logging
# Set up logging configuration
logging.basicConfig(
level=logging.DEBUG, # Use DEBUG to capture all log levels
format='%(asctime)s %(levelname)s %(message)s'
)
def update_min_instances(run_service, service_name, region, min_instances, always_allocated):
project_id = os.environ.get('GCP_PROJECT')
service_path = f"projects/{project_id}/locations/{region}/services/{service_name}"
logging.info(f"Updating service: {service_path} to minInstances: {min_instances}")
# Fetch the current service configuration
service = run_service.projects().locations().services().get(name=service_path).execute()
logging.debug(f"Fetched service configuration: {json.dumps(service)}")
service_annotations = service['metadata'].get('annotations', {})
service_annotations['run.googleapis.com/minScale'] = str(min_instances)
service['metadata']['annotations'] = service_annotations
logging.debug(f"Updated annotations on template: {service_annotations}")
# Update the CPU allocation in the revision template
cpu_throttling = 'false' if always_allocated else 'true'
annotations = service['spec']['template']['metadata'].get('annotations', {})
annotations['run.googleapis.com/cpu-throttling'] = cpu_throttling
service['spec']['template']['metadata']['annotations'] = annotations
logging.debug(f"Updated CPU allocation annotations: {annotations}")
# Remove fields that are not allowed in the request
if 'status' in service:
del service['status']
if 'spec' in service and 'traffic' in service['spec']:
del service['spec']['traffic']
if 'metadata' in service and 'generation' in service['metadata']:
del service['metadata']['generation']
try:
# Send the update request
response = run_service.projects().locations().services().replaceService(
name=service_path,
body=service
).execute()
logging.info(f"Service update response: {json.dumps(response)}")
# Check if the response includes the updated minScale
new_min_scale = response.get('spec', {}).get('template', {}).get('metadata', {}).get('annotations', {}).get('run.googleapis.com/minScale')
logging.info(f"New minScale after update: {new_min_scale}")
except Exception as e:
logging.error(f"Failed to update service: {e}")
@functions_framework.http
def scale_down_instances(request):
try:
service_config = json.loads(os.environ.get('SERVICE_CONFIG'))
logging.info(f"SERVICE_CONFIG: {service_config}")
credentials, project = google.auth.default(scopes=['<https://www.googleapis.com/auth/cloud-platform>'])
run_service = discovery.build('run', 'v1', credentials=credentials)
for service_name, config in service_config.items():
logging.info(f"Scaling down service: {service_name}")
update_min_instances(
run_service,
service_name,
config['region'],
0, # Set minInstances to 0
False
)
return ('Scaled down instances to 0.', 200)
except Exception as e:
logging.exception("An error occurred: %s", e)
return ('An error occurred.', 500)
@functions_framework.http
def scale_up_instances(request):
try:
service_config = json.loads(os.environ.get('SERVICE_CONFIG'))
logging.info(f"SERVICE_CONFIG: {service_config}")
credentials, project = google.auth.default(scopes=['<https://www.googleapis.com/auth/cloud-platform>'])
run_service = discovery.build('run', 'v1', credentials=credentials)
for service_name, config in service_config.items():
logging.info(f"Scaling up service: {service_name} to minInstances: {config['minInstances']}")
update_min_instances(
run_service,
service_name,
config['region'],
config['minInstances'], # Set to specified minInstances
True
)
return ('Scaled up instances to specified minInstances.', 200)
except Exception as e:
logging.exception("An error occurred: %s", e)
return ('An error occurred.', 500)
Conclusion
Bringing it all together, this article walked through a customized automated scaling solution in Cloud Run and showed a practical application resulting in major cost reductions.
By reducing idle instances during low-demand periods, we achieved significant cost savings without compromising service quality. To ensure ongoing success, the team implemented comprehensive monitoring through Cloud Monitoring, setting up custom alerts and dashboards to track both performance metrics and availability after implementing the solution.
Our experts at SZNS are passionate about ensuring that your GCP solutions are robust, performant, and cost-effective. If you're looking for guidance or support in implementing similar solutions, don't hesitate to get in touch!


