Dataprep to BigQuery
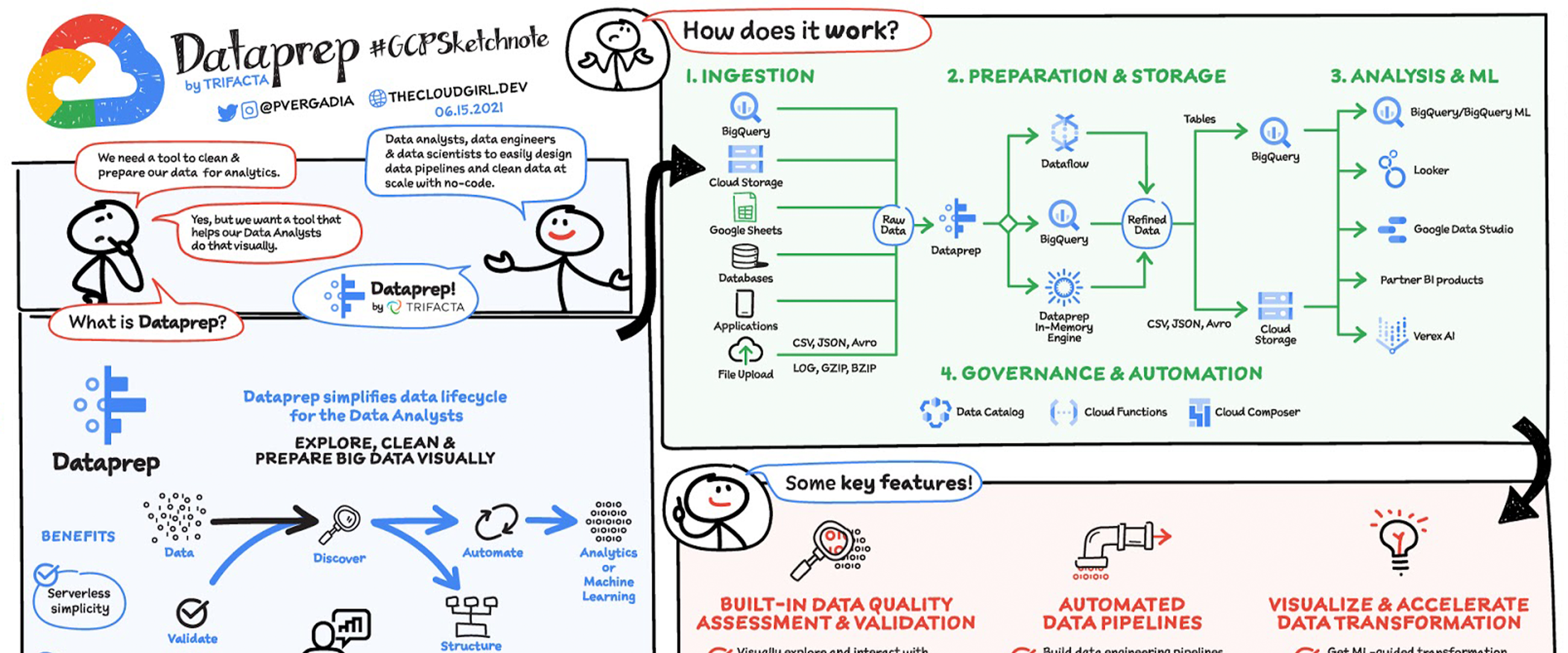
Dataprep, developed by Trifacta, is a fully-managed service to speed up data exploration, cleaning, and transformation. The platform provides an intuitive UI to define data sources, transformation steps, and export to other data storage systems (eg: Cloud Storage, BigQuery).
Dataprep reduces reliance and bottlenecks on dedicated data engineers and allows more team members to prepare data for analysis quicker.
In this blog we'll explore some basic concepts and review a demo of how we used Dataprep internally to quickly import and transform data for analytics.
Concepts & Terms
Data preparation
Data is vast and comes in many shapes and forms. The following steps are needed before the data is ready for analysis.
- Data Discovery - Where is data stored, how does it look, what is the profile of fields
- Data Cleaning - How to standardize column data types/formats and handle missing values
- Data Enrichment - How to augment the dataset(s) with other data sources. Such an example is correlating
- Data Validation - Check for any data inaccuracies or inconsistencies
Dataprep
- Flow - Represents an end-to-end data preparation job. Flows define the import dataset(s), the data preparation steps, and where to export the data
The Data
For this demo we’ll consolidate my team’s GCP certification data. I have datasets with (1) my employees information, (2) GCP certification information, and (3) GCP certification exam attempts for each employee.
All data will be uploaded into a GCP Storage bucket.
The final data will be ingested into BigQuery. Looker Studio will import from BigQuery to analyze gaps in capabilities and upcoming expiration of certifications.
Users
Our employee information is a CSV file with their employee ID, name, and office location.
id,name,location
1,Bruce Wayne,"New York, New York"
2,Clark Kent,"Los Angeles, California"
3,Barry Allen,"San Diego, California"
4,Harleen Quinzel,"New York, New York"
5,Diane Prince,"Austin, Texas"
6,Christopher Smith,"Washington, District of Columbia"
7,Robert DuBois,"Washington, District of Columbia"Certifications
A CSV file for each GCP certification and the category for the certification
Id,certificate_name,category
1,Digital Leader,Foundational
2,Cloud Engineer,Associate
3,Architect,Professional
4,Database Engineer,Professional
5,Developer,Professional
6,Data Engineer,Professional
7,DevOps Engineer,Professional
8,Security Engineer,Professional
9,Network Engineer,Professional
10,Workspace Administrator,Professional
11,Machine Learning Engineer,Professional
Exam Results
A CSV file for exam results for employees, when they took an exam, which certification, and whether they passed. Note that the date column has different formats.
employee,date_of_exam,cert_id,pass
6,06/13/2024,8,TRUE
2,"April 10, 2023",8,TRUE
1,10/10/2022,8,TRUE
7,2024-08-02,5,TRUE
7,2022-12-26,6,TRUE
7,2024-09-10,2,FALSE
1,01 May 22,10,FALSE
6,"January 01, 2024",3,TRUE
2,"February 28, 2023",10,FALSE
3,04 August 2023,5,TRUE
6,"June 12, 2023",11,TRUE
3,23 March 2024,1,FALSE
5,11/16/2023,8,TRUE
5,"Feb 16, 2022",2,TRUE
3,16 May 2024,2,TRUE
3,03/03/2024,10,FALSE
5,"June 20, 2024",3,FALSE
7,"August 01, 2024",4,FALSE
Demo
We’ll first create a flow. A flow in Dataprep is a container for the data preparation to include (1) importing the data, (2) cleaning/transforming/enriching the data, and (3) exporting the data.
Import Data
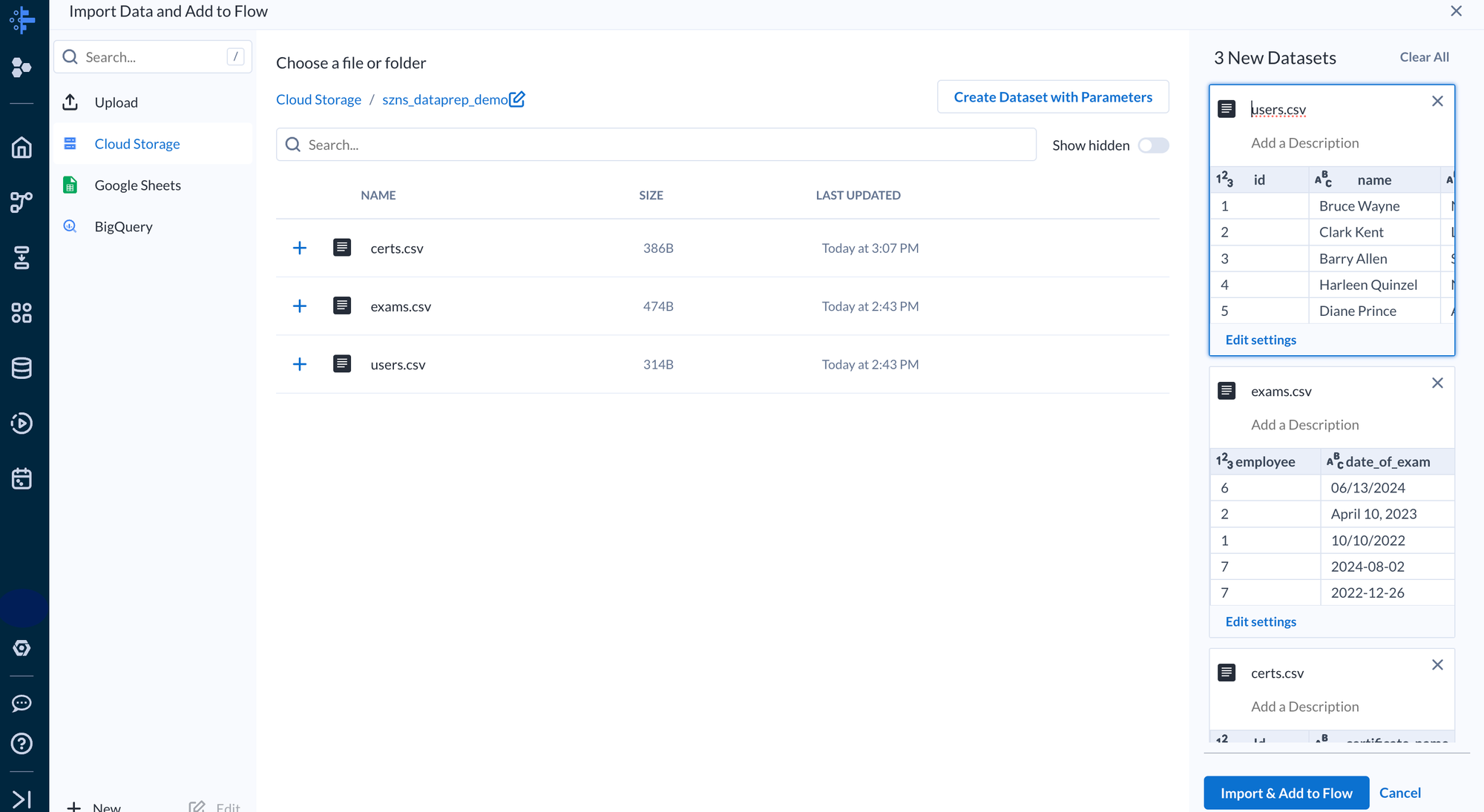
Once a new flow is created we need to import our data. Dataprep provides out of the box integrations with data sources such as Cloud Storage, Google Sheets, BigQuery, and native file uploads.
For this demo we’ll import from Google Cloud Storage. During import Dataprep does an initial effort to profile the incoming data. Each file imported will be treated as a separate dataset.
Data Enrichment
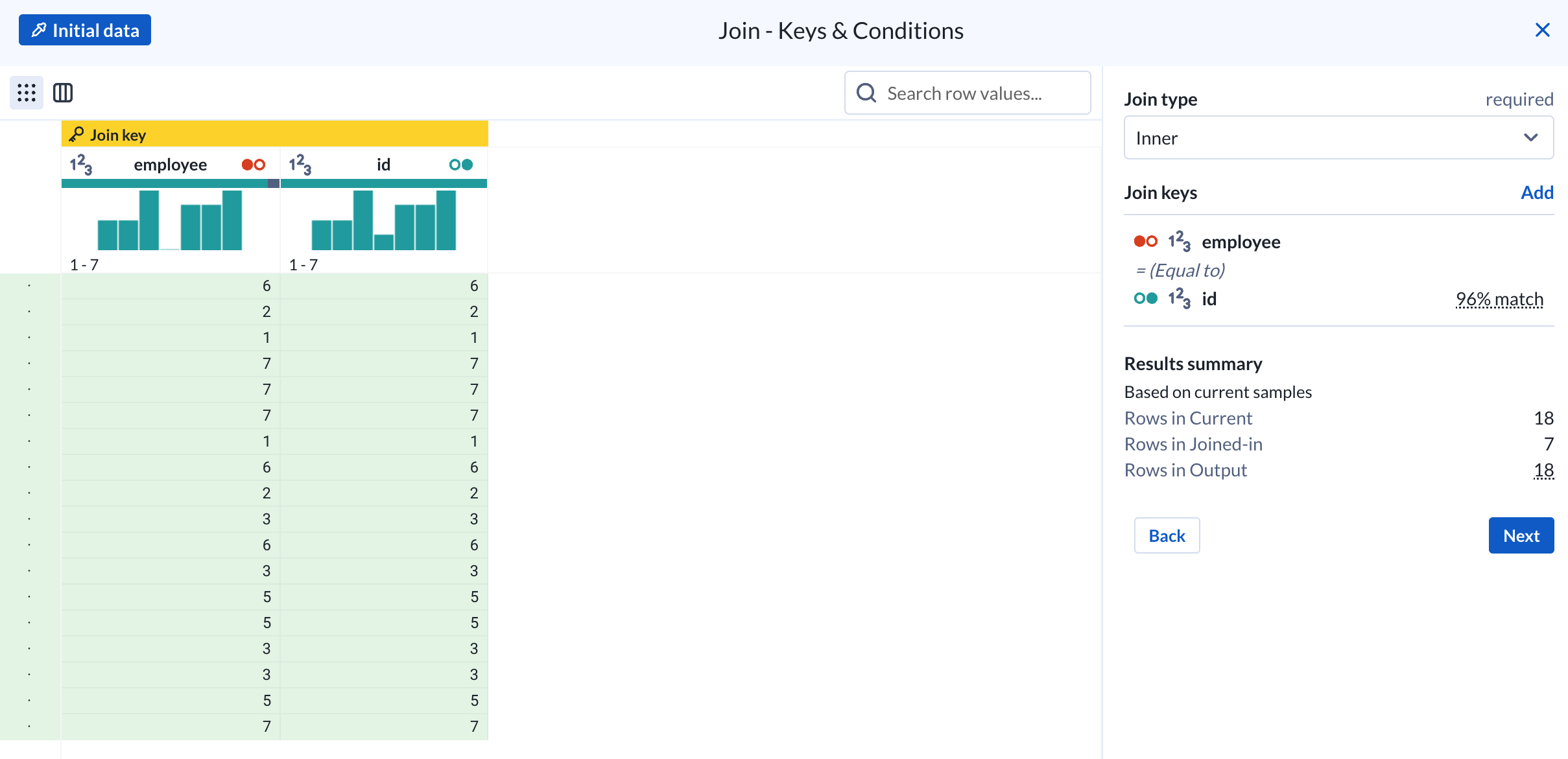
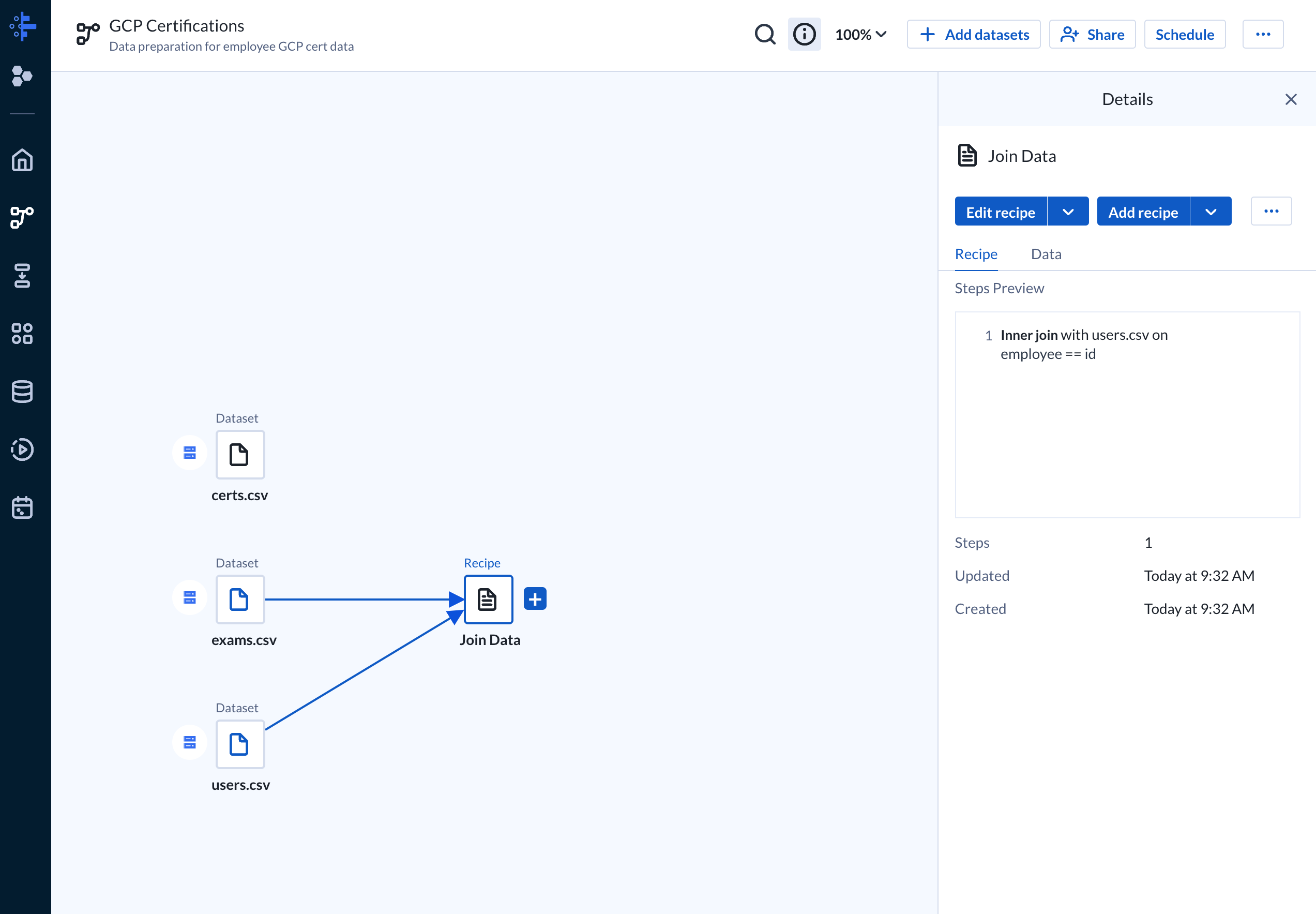
Since the exam data only contains the employee ID that took the exam we want to enrich it with the user (eg: employee) dataset to add information such as the employee name and their office location. To achieve this we’ll utilize a join step which combines two datasets based on a common key. We can select our exam dataset and select “Add Join”.
We’ll do an inner join to join based on the employee column from the exam dataset and the id column from the user (ie: employee) dataset. Notice as we join a convenient preview of the result and data profile is provided a subset of the data before changes are applied.
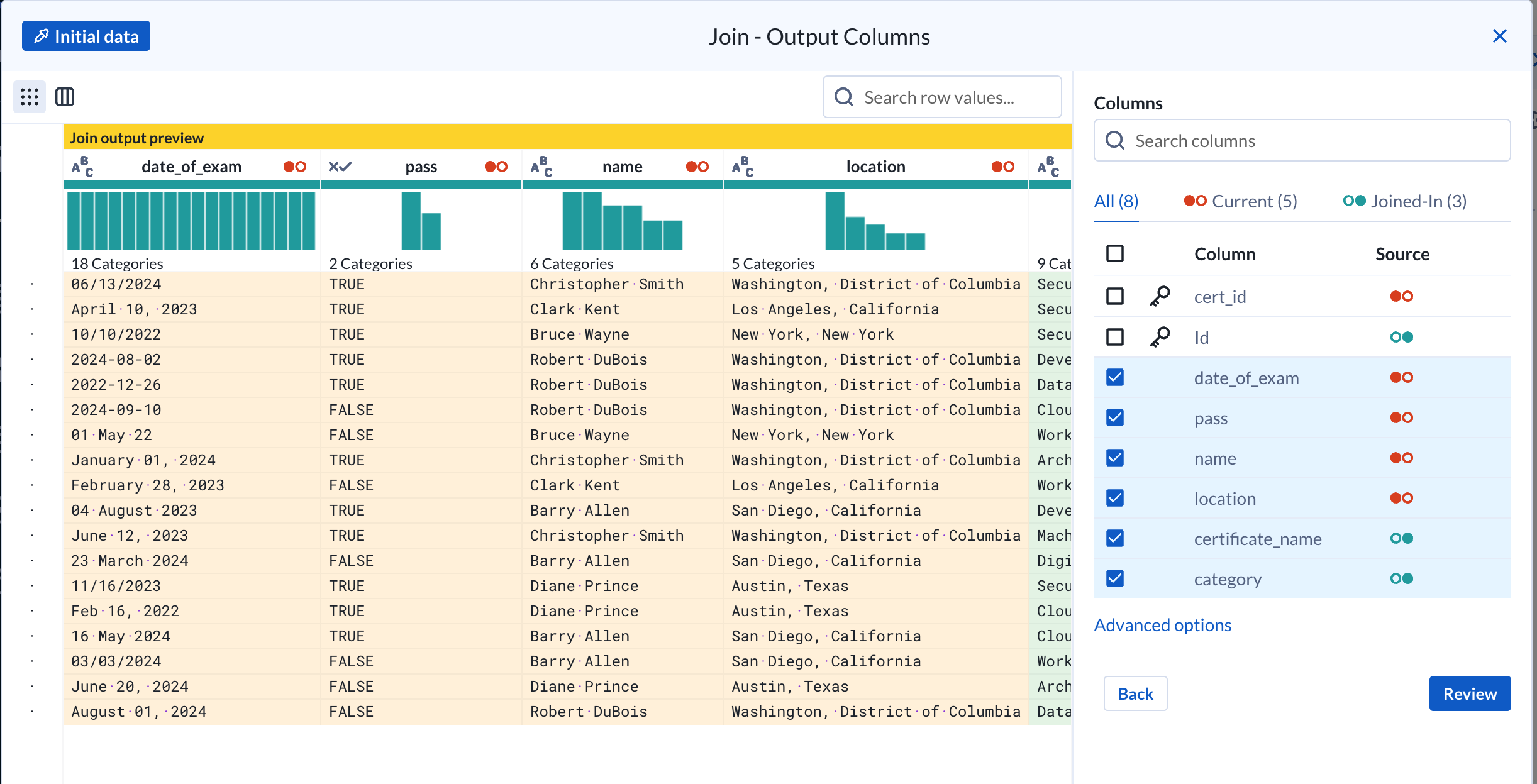
Our resulting flow should look like the following. The join added a recipe that takes in our exams and user dataset. A recipe is a data preparation stage that can include one (1) or more steps to manipulate the data.
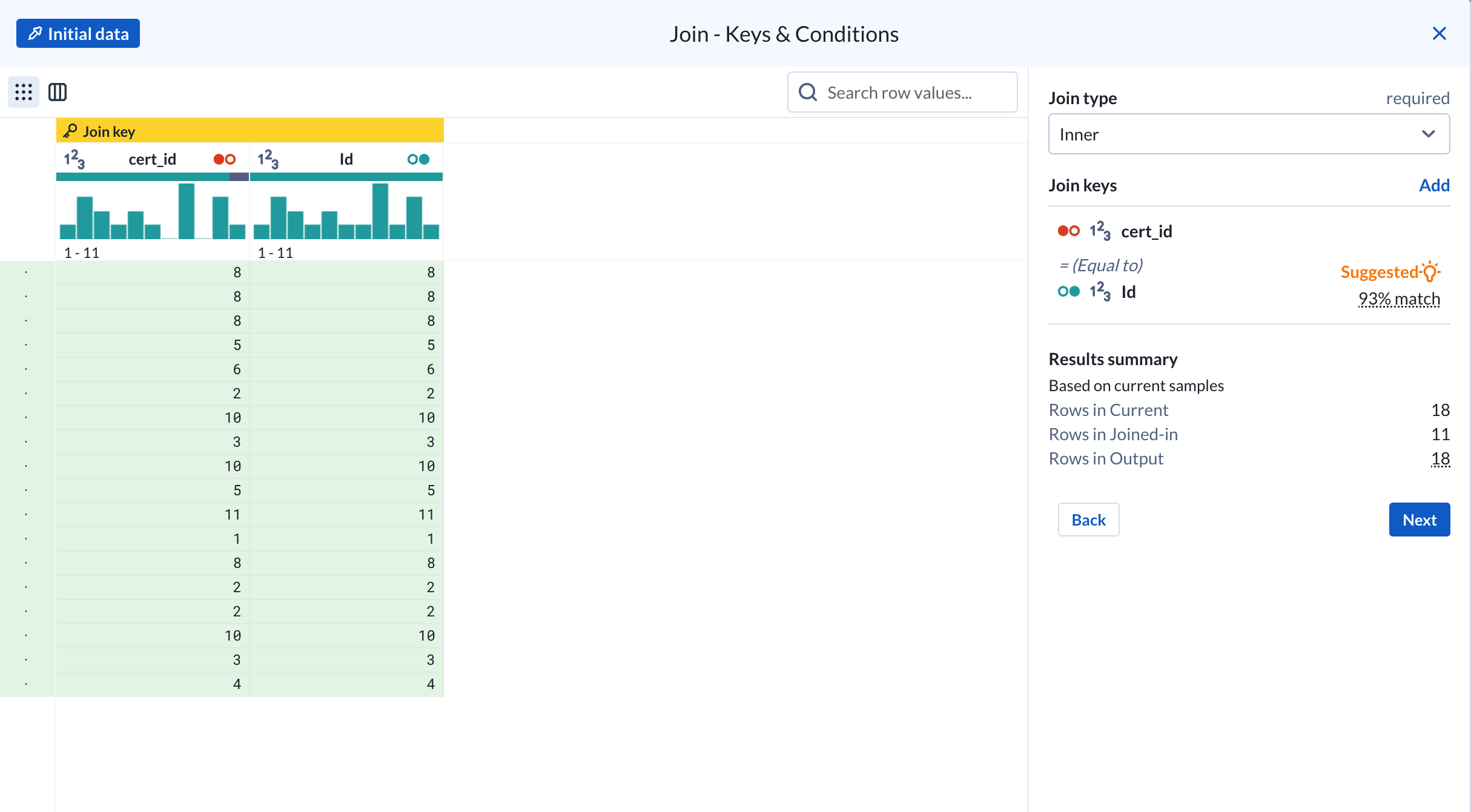
Since the exam data only contains certificate IDs we’ll apply the same inner join to add certification information (ie: certification name, category) as another step to the “Join Data” recipe.
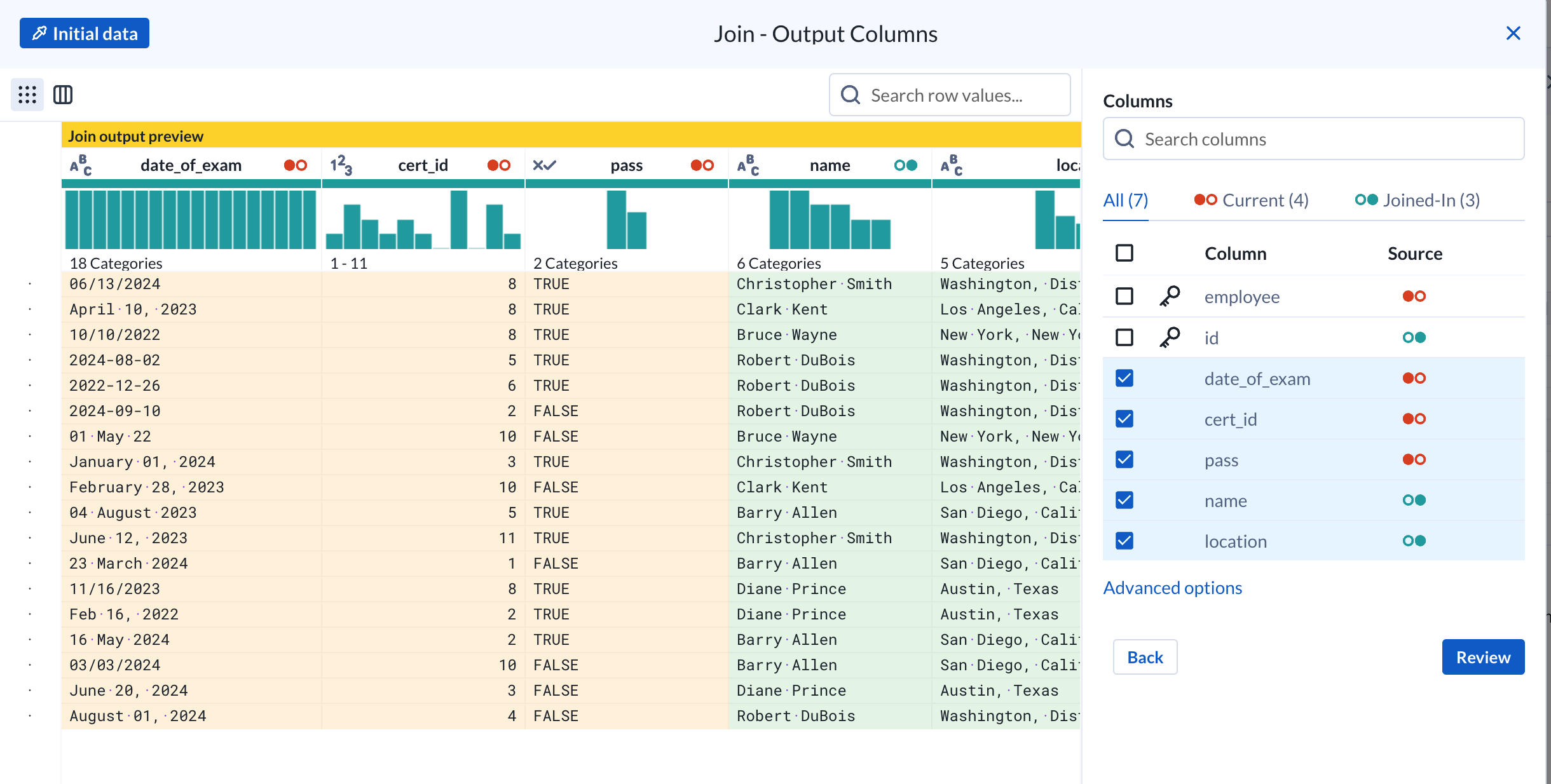
The Flow now takes in all datasets as inputs.
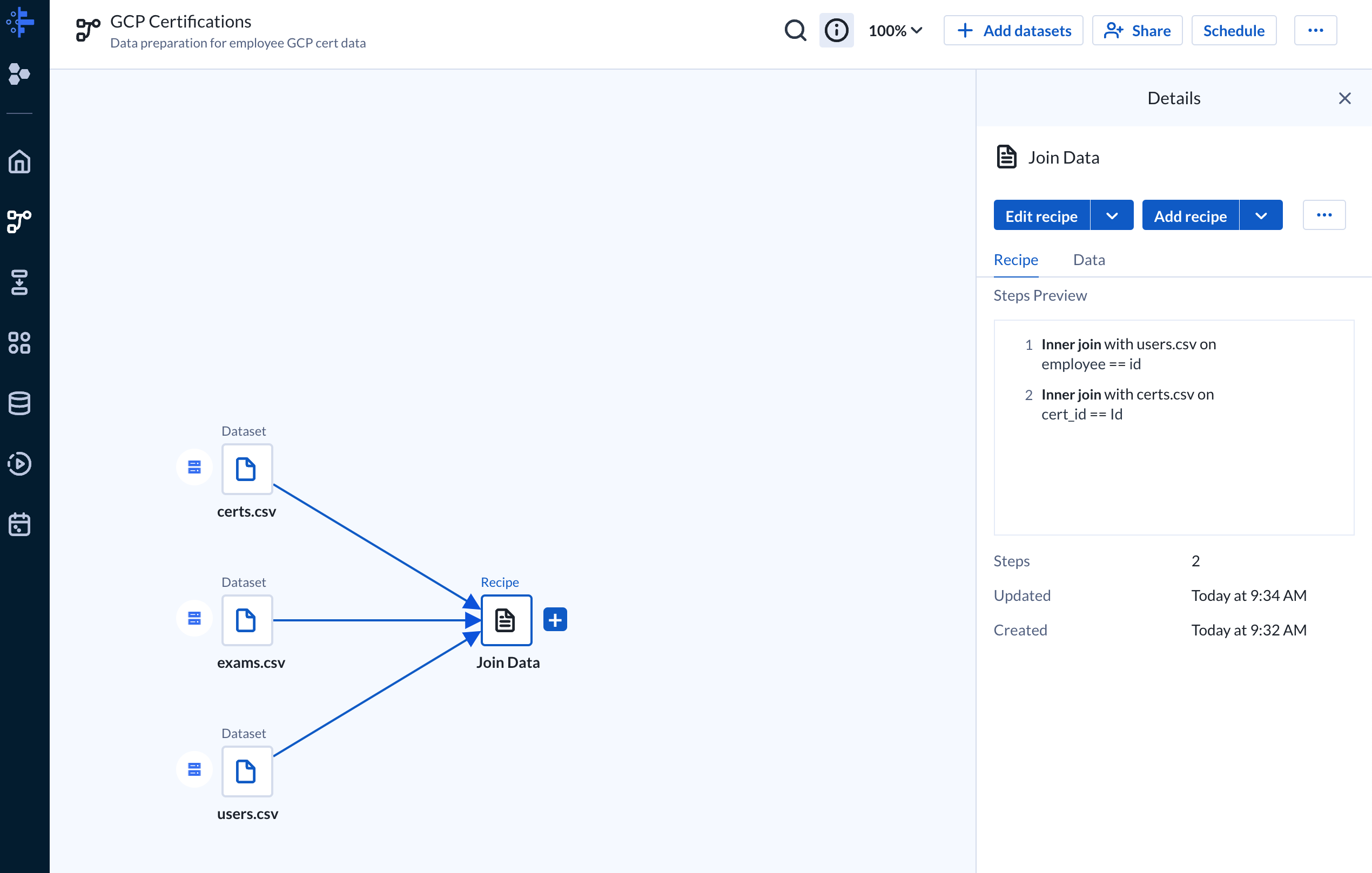
Data Cleaning
From the initial exam dataset the date_of_exam column had different date formats. This is unideal so we will standardize the column. We’ll use the same “Join Data” recipe and add a step after the join steps.

There are a lot of useful prebuilt transformations. For this we’ll use the “Date format” transformation.
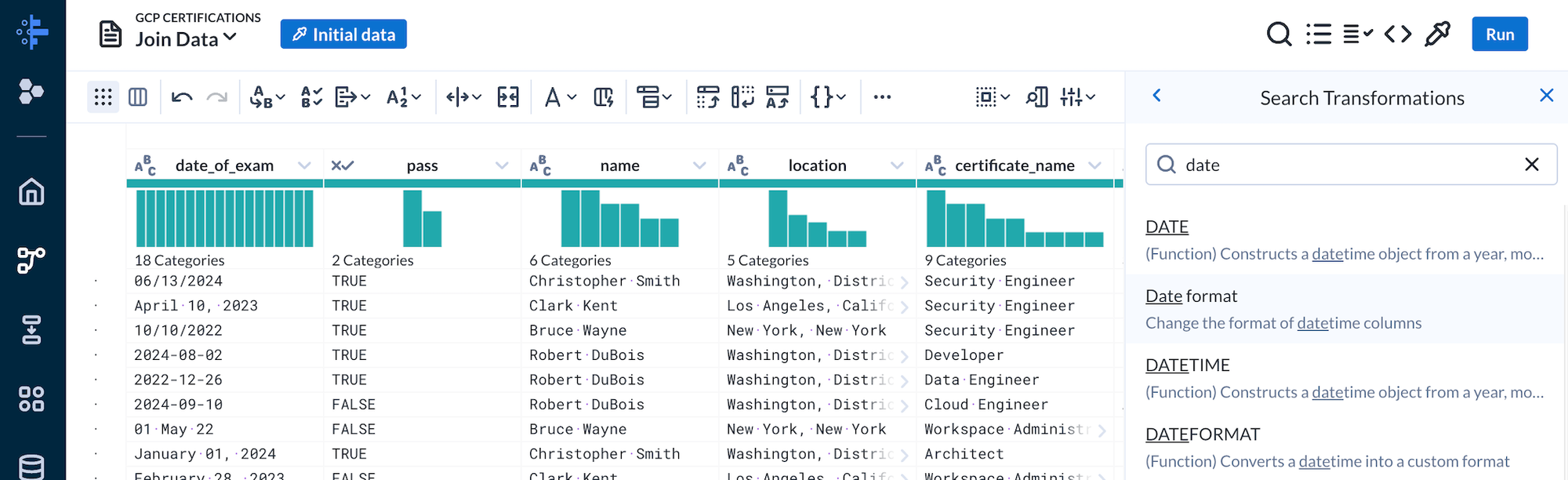
We selected the date_of_exam column and choose the output format as yyyy-MM-dd. The preview will dynamically update and the transformation will best effort normalize the data. For this transformation we need to set custom input formats for the transformation to parse and transform some cases it couldn’t natively transform.
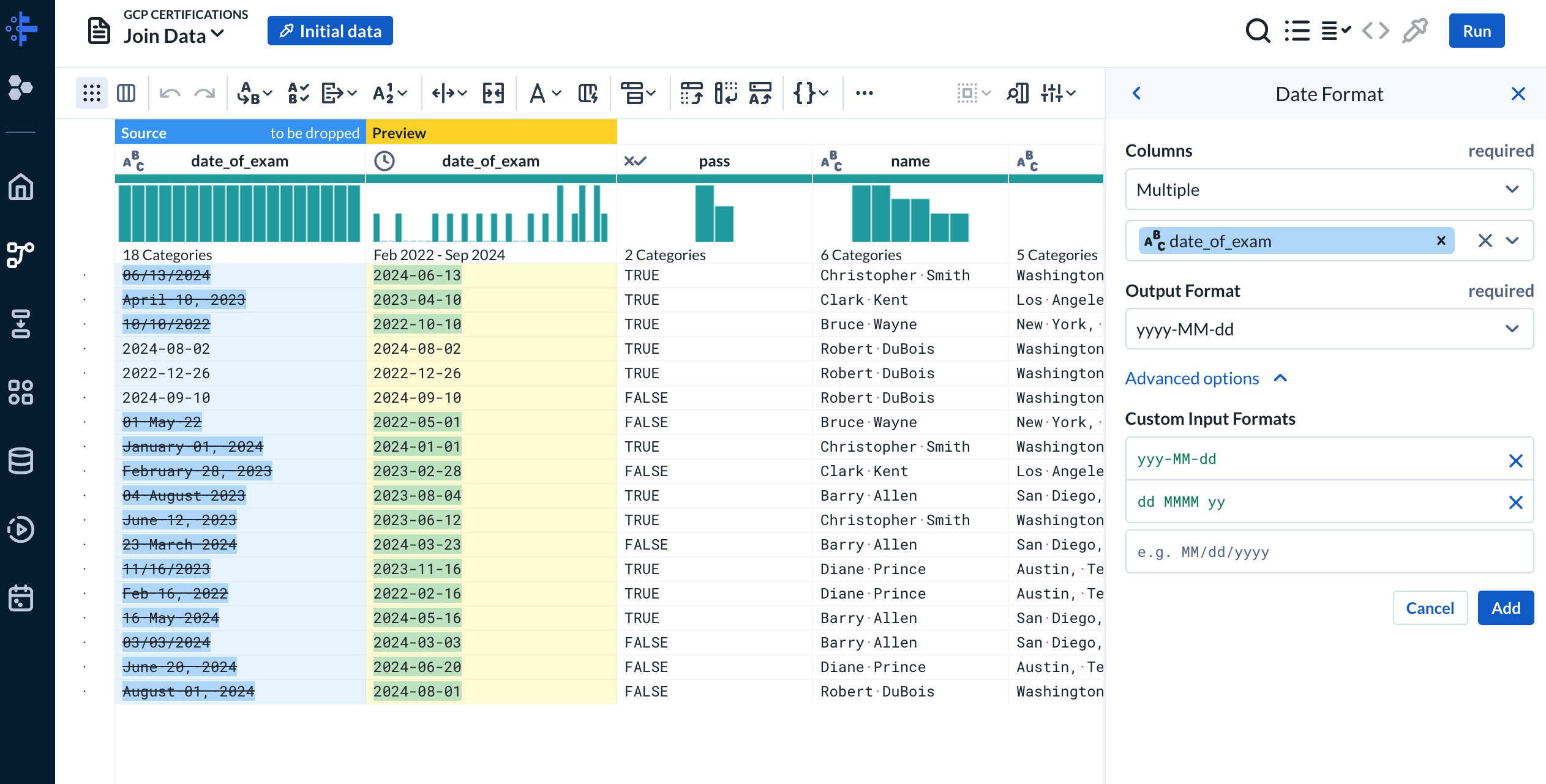
date_of_exam columnLastly we’ll add a new column to indicate if a certificate is still active. We can use the “Conditional Column” transformation to create an is_active column and set the value conditionally. If date_of_exam is less than or equal to the current time we’ll set the is_active to false since certificates expire every two (2) years.
NOTE: There is an error here…we should’ve have defaulted to false if the pass column value was false that indicated the person did not pass the exam.
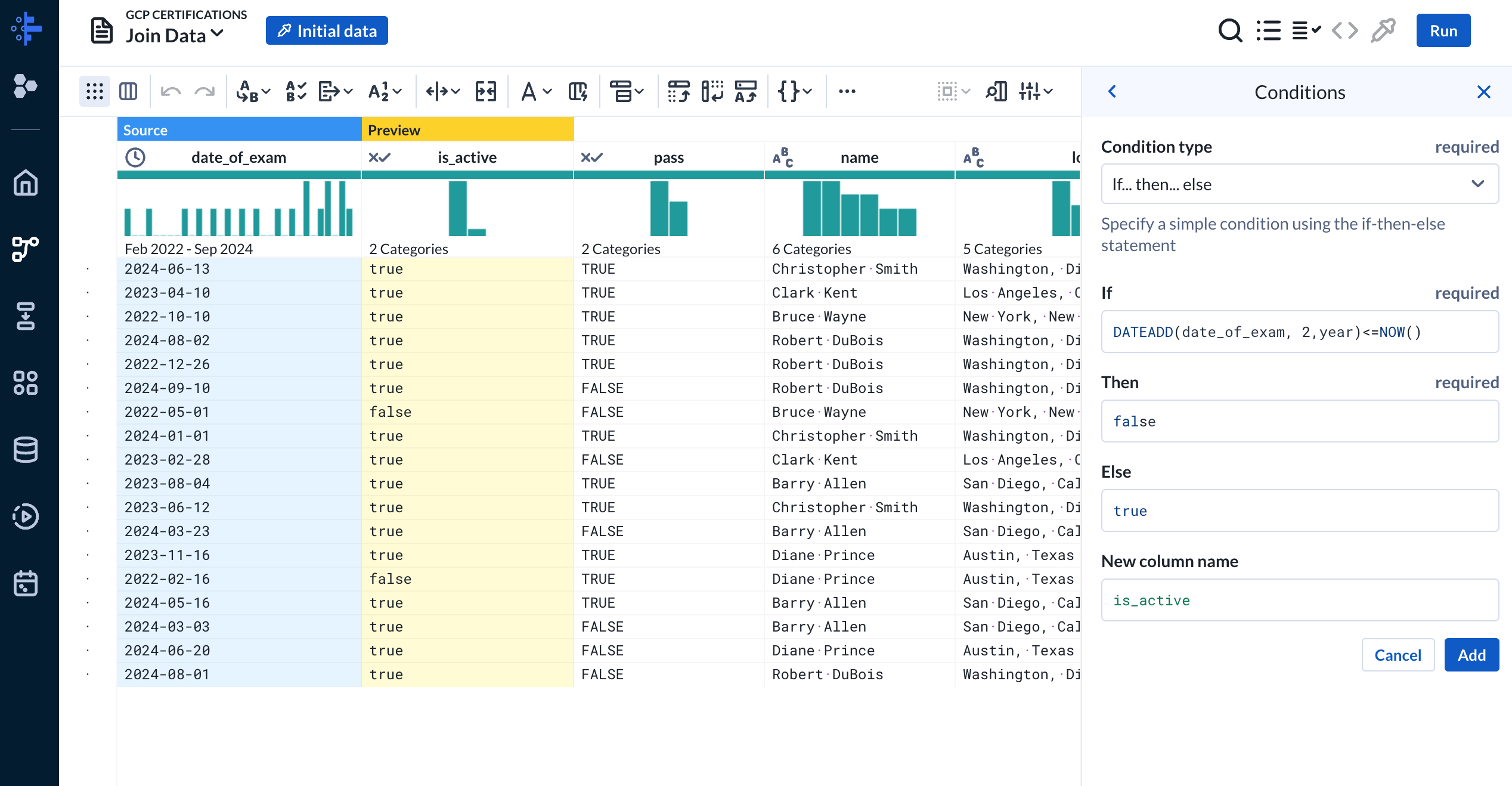
is_active columnRunning the flow
Return to the flow and add an output to the “Join Data” recipe. The output defines where to export the transformed data. For our case we configured to output to BigQuery.
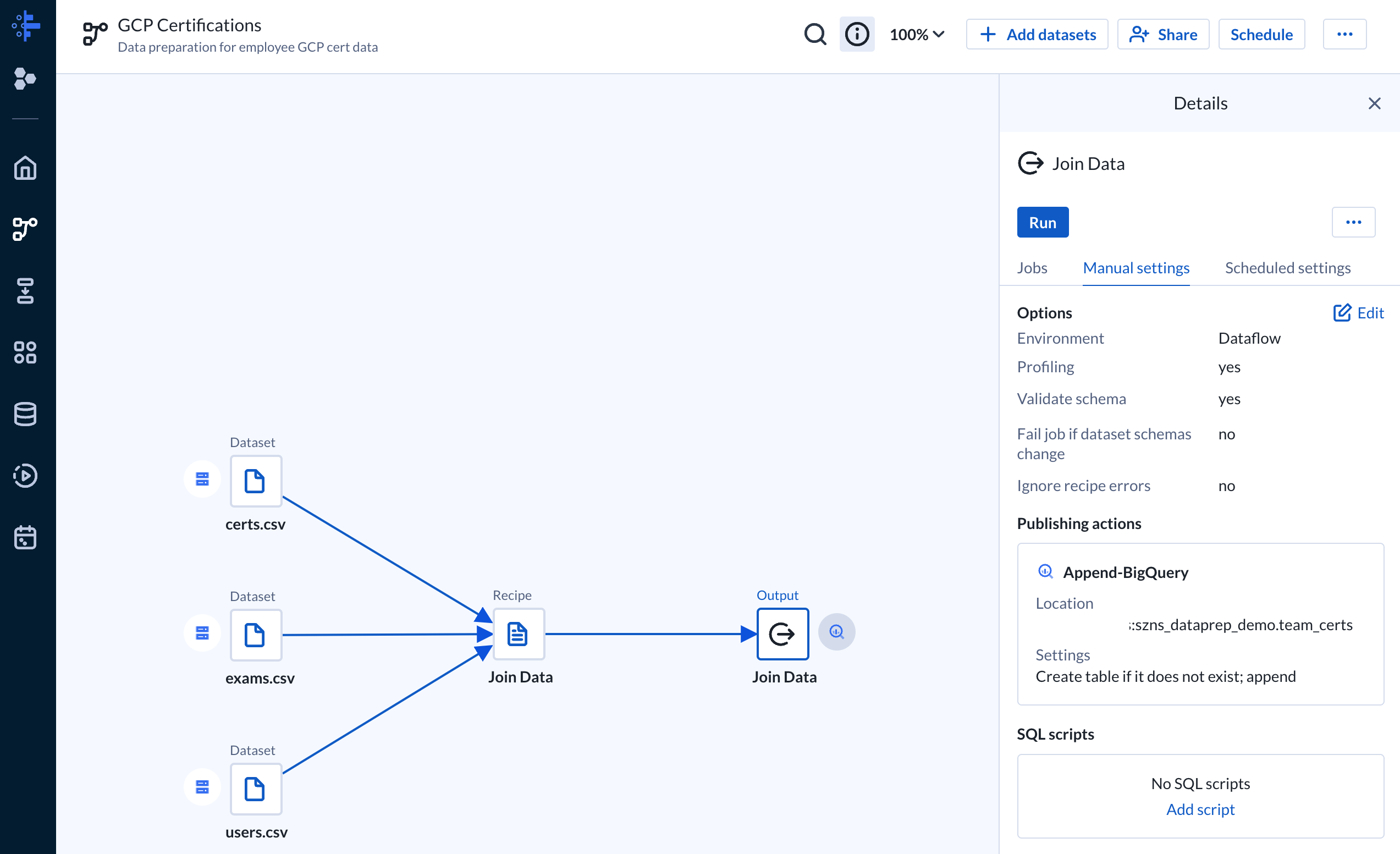
On the BigQuery output we can select “Run” to start the dataprep flow. This will translate our transformations and deploy Dataflow jobs. Once the job completes Dataprep provides a convenient summary to show any issue to include pipeline failures, data mismatches, and data inconsistencies.
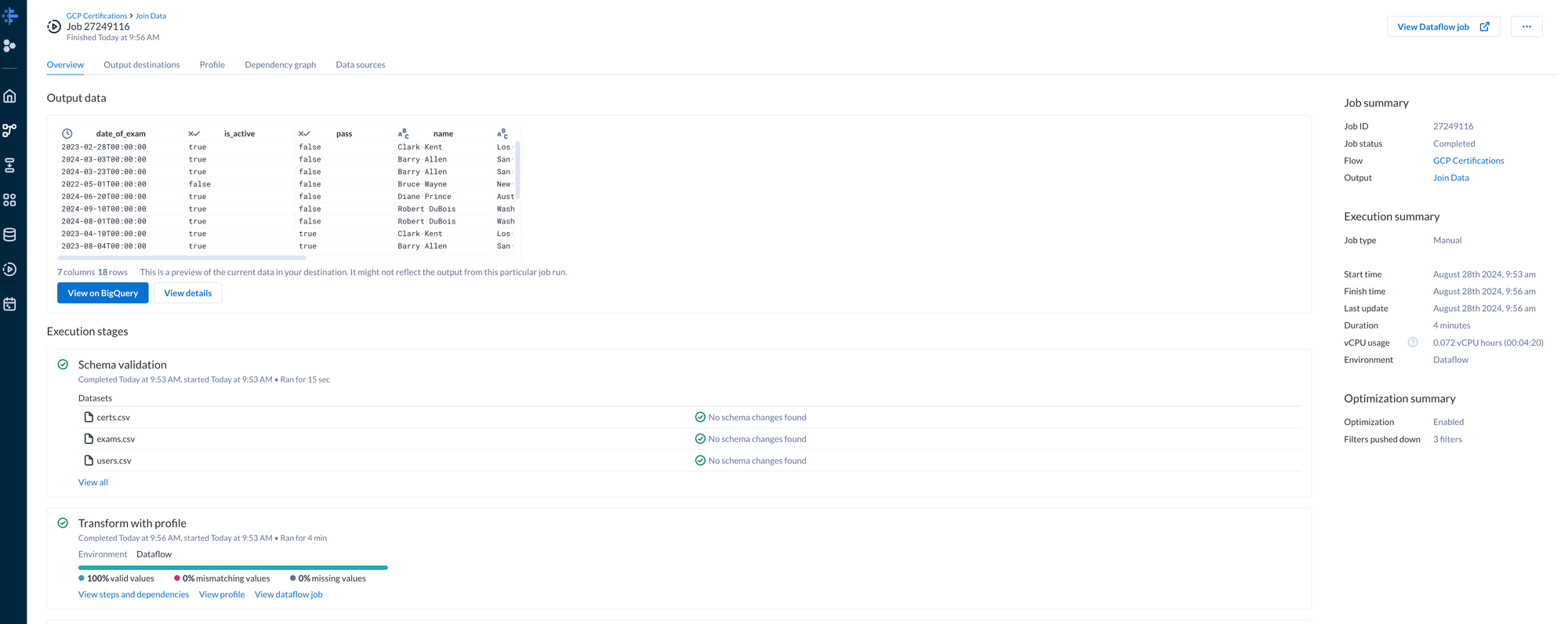
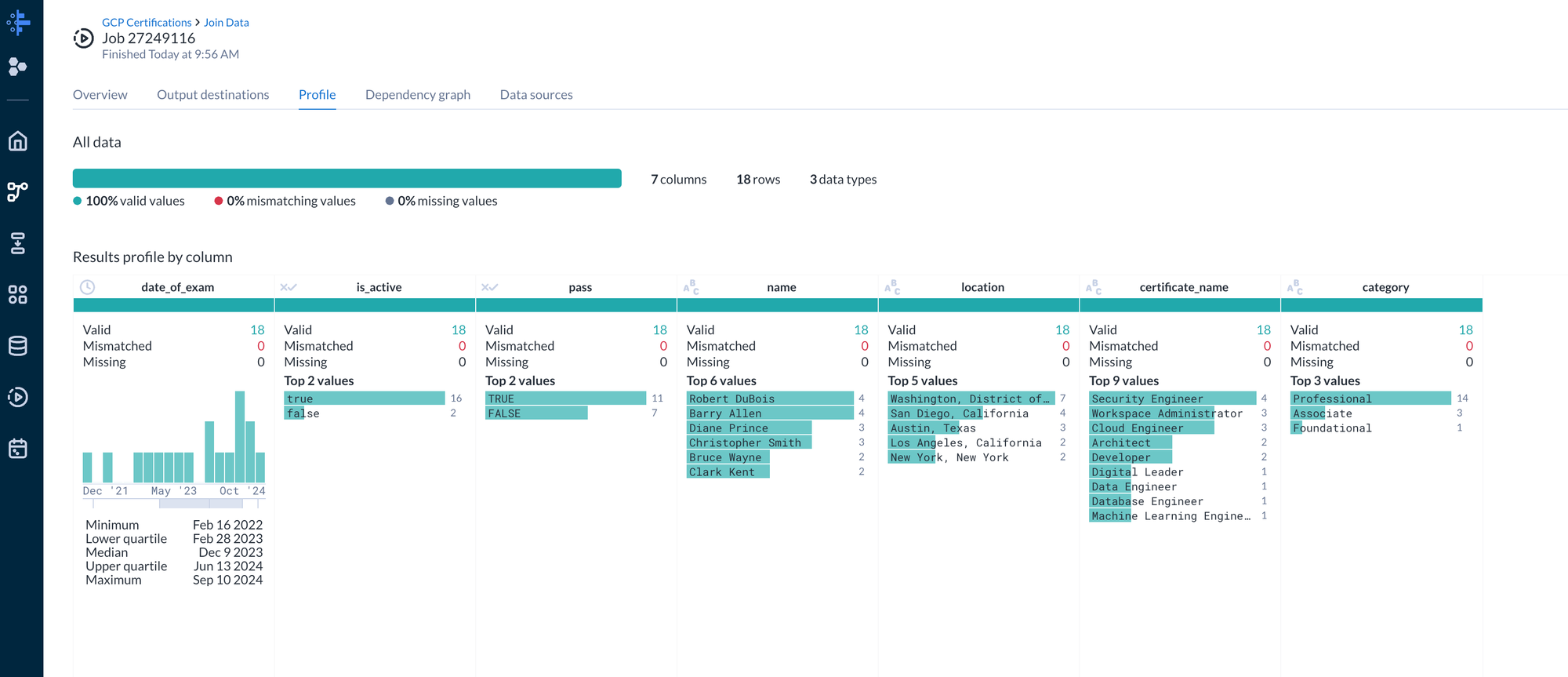
With the data cleaned we can now utilize the BigQuery dataset for analytics and ultimate create reports in Looker Studio.
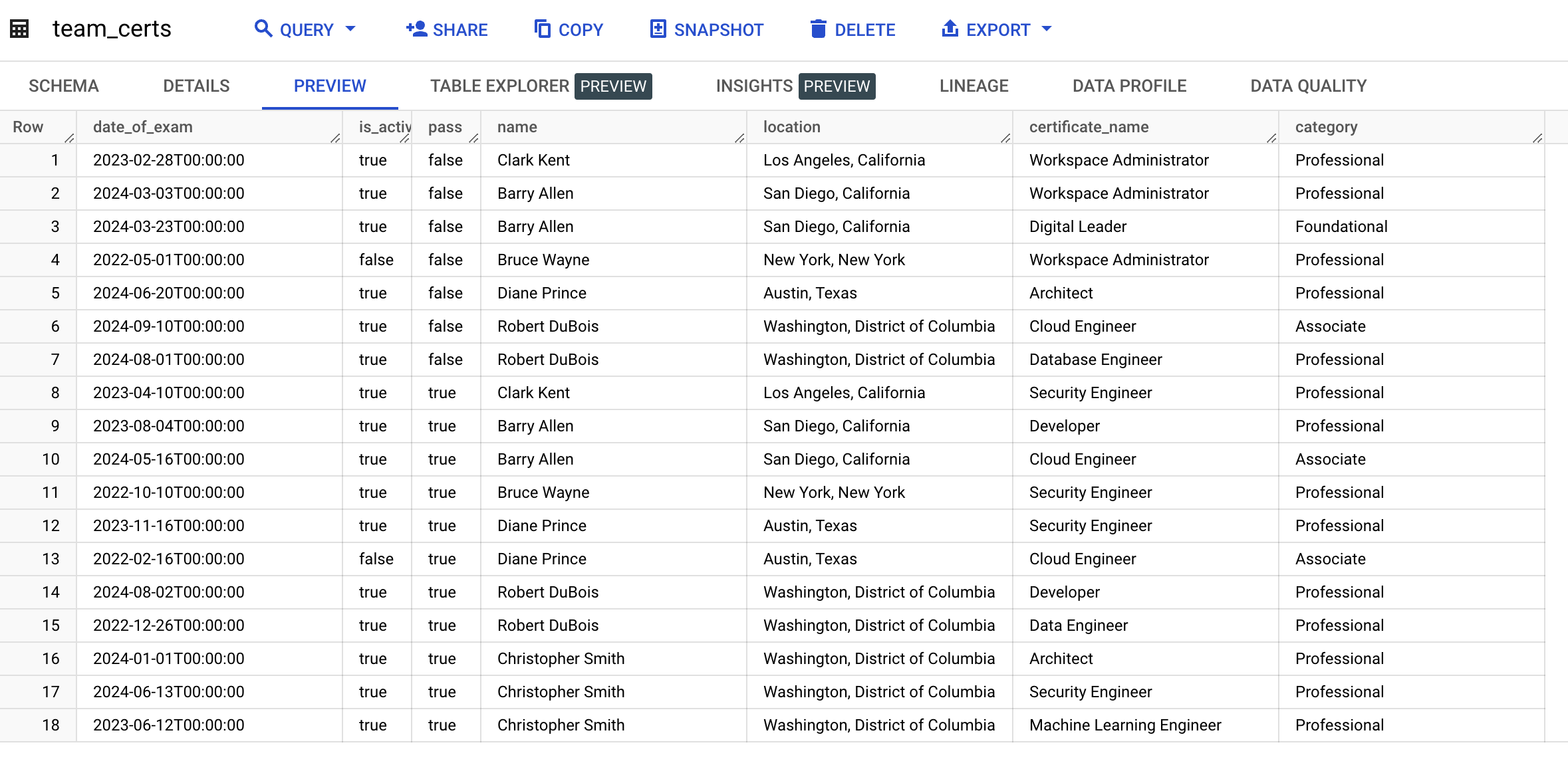
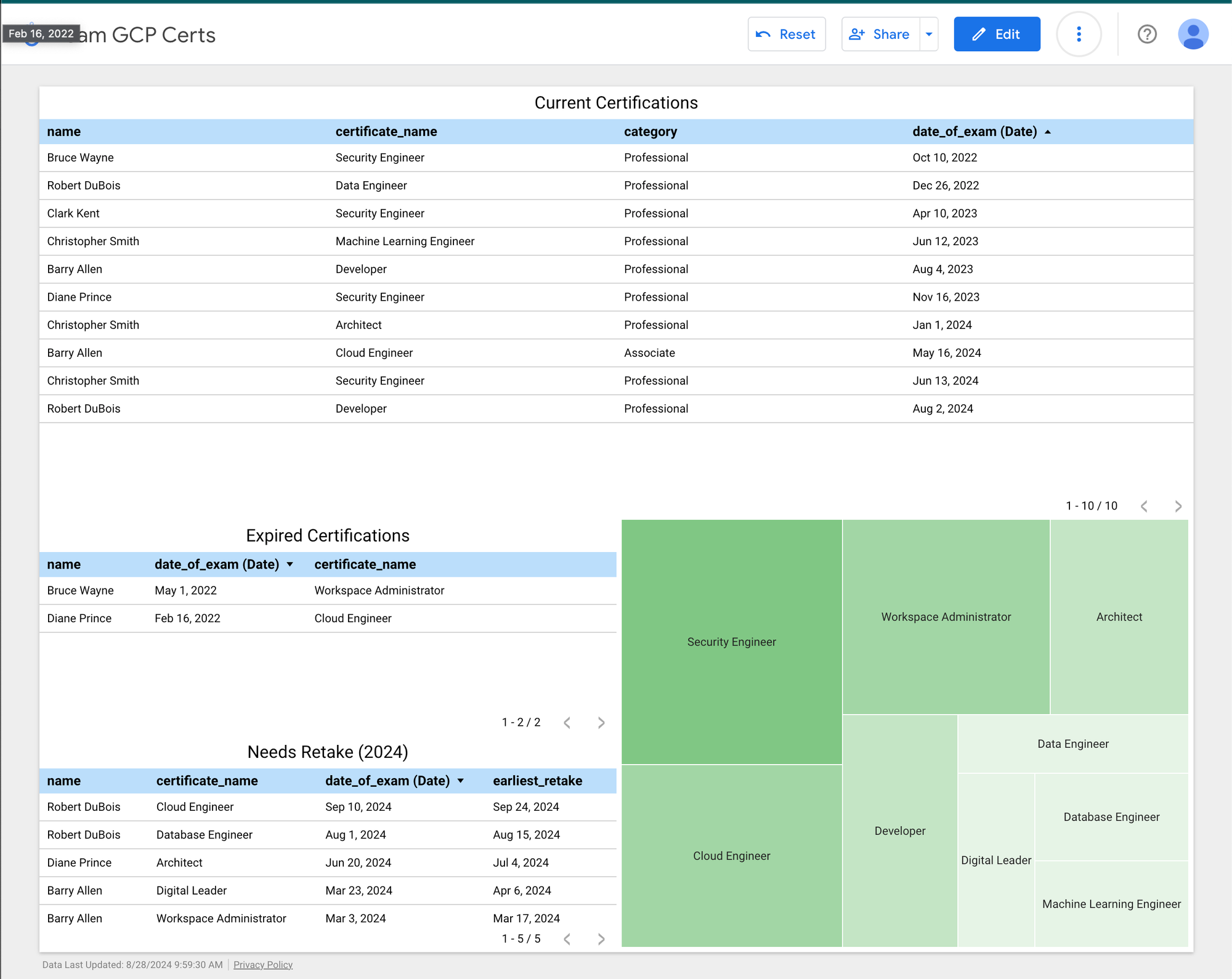
Conclusion
In this demo we were able to take our exam data, enrich it with employee and certification data, and upload clean data ready for analysis. This process required no code and infrastructure management which allowed our team to fully focus on data preparation.
Resources
Additional references to get started in Dataprep.
Dataprep documentation
GCP Marketplace Offering Post


