Document Field Extraction with Google's Document AI
SZNS Solutions (pronounced "seasons") is a certified Google Cloud Partner and technology consulting firm with deep engineering expertise on building cloud-native solutions and solving difficult technical problems.
You can find more information at our website https://szns.solutions/ or email us at info@szns.solutions.
Overview
One of our clients recently came to us asking for help automating a manual action in their workflow. With digitally scanned forms, the client was manually copying form entries into their enterprise resource planning (ERP) system. This process was prone to human error and typos, especially with certain strings exceeding 16 characters.
SZNS researched a few different options to automate the text extraction process for our client. We concluded that Document AI from the Google Cloud Platform would be the best solution for the client. Document AI was fast to get running and integrated well into the client's GCP environment.
Today, I’ll go through SZNS’ learnings about Document AI as well as show how quickly you can implement a Document AI solution to extract text from digitized documents.
Document AI
In 2020, Google Cloud introduced the Document AI Platform to help companies solve their document processing problems with low cost AI. Document AI started with 10 “processors” — Google’s concept of an engine that joins the document file and AI model which performs document processing and understanding actions. As of this writing, Document AI has 16 processors to choose from with each one targeted toward a specific use case. You can find the full list of processors here.
Document AI provides custom processors which you can label and train, but where Document AI really shines is in its pre-trained processors. Pre-trained processors work out of the box without needing any additional training data which avoids one of the biggest hurdles of ML/AI development — gathering and sanitizing the large volume of data needed to train good models. Even the custom processors work well with relatively small data sets. In SZNS’ testing of the custom extractor, with only 25 training documents, the custom processor still resulted in a F1 score above 0.9.
Two of Document AI’s processors applied to our client’s text extraction use case. In the next sections, I will walk through creating and using the Form Parser which comes pre-trained as well as training a Custom Extractor to show how quickly and accurately we can implement solutions to automate document text extraction with Document AI.
How To Use the Form Parser
The Form Parser is one of the pre-trained processors that Document AI provides specifically for text extraction around form type documents. Let’s walk through the steps to create and use the form parser.
First, we’ll start at the Document AI’s “Processor Gallery” page where you can view the full set of processors available and select the one you would like to use.
We’ll click on the Create Processor link under the Form Parser which opens up a panel to name the processor.
Once we name and create it, our “OneClickFormParser” is ready to go!
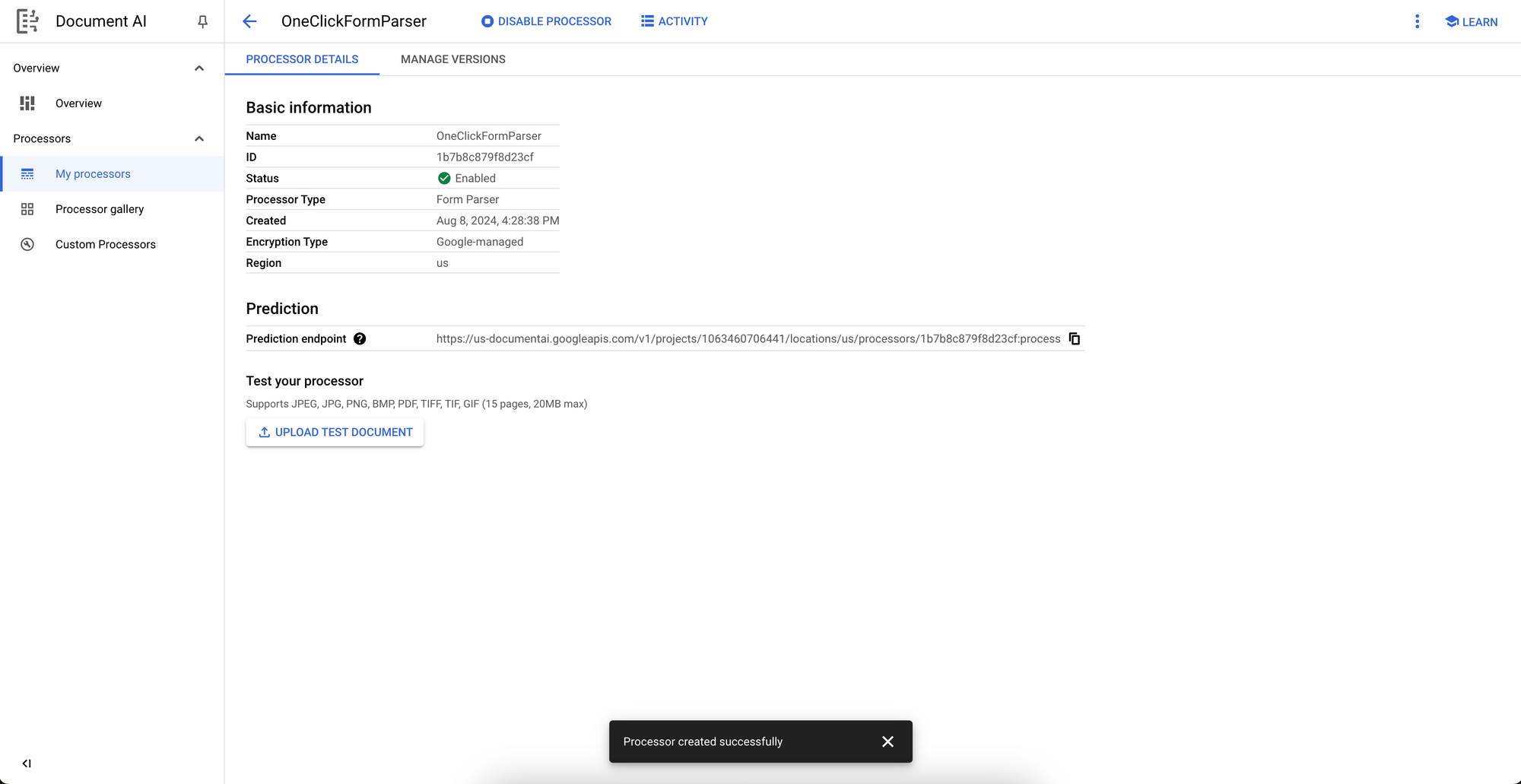
We’ll test the pre-trained processor with an example TICA pedigree form I created.
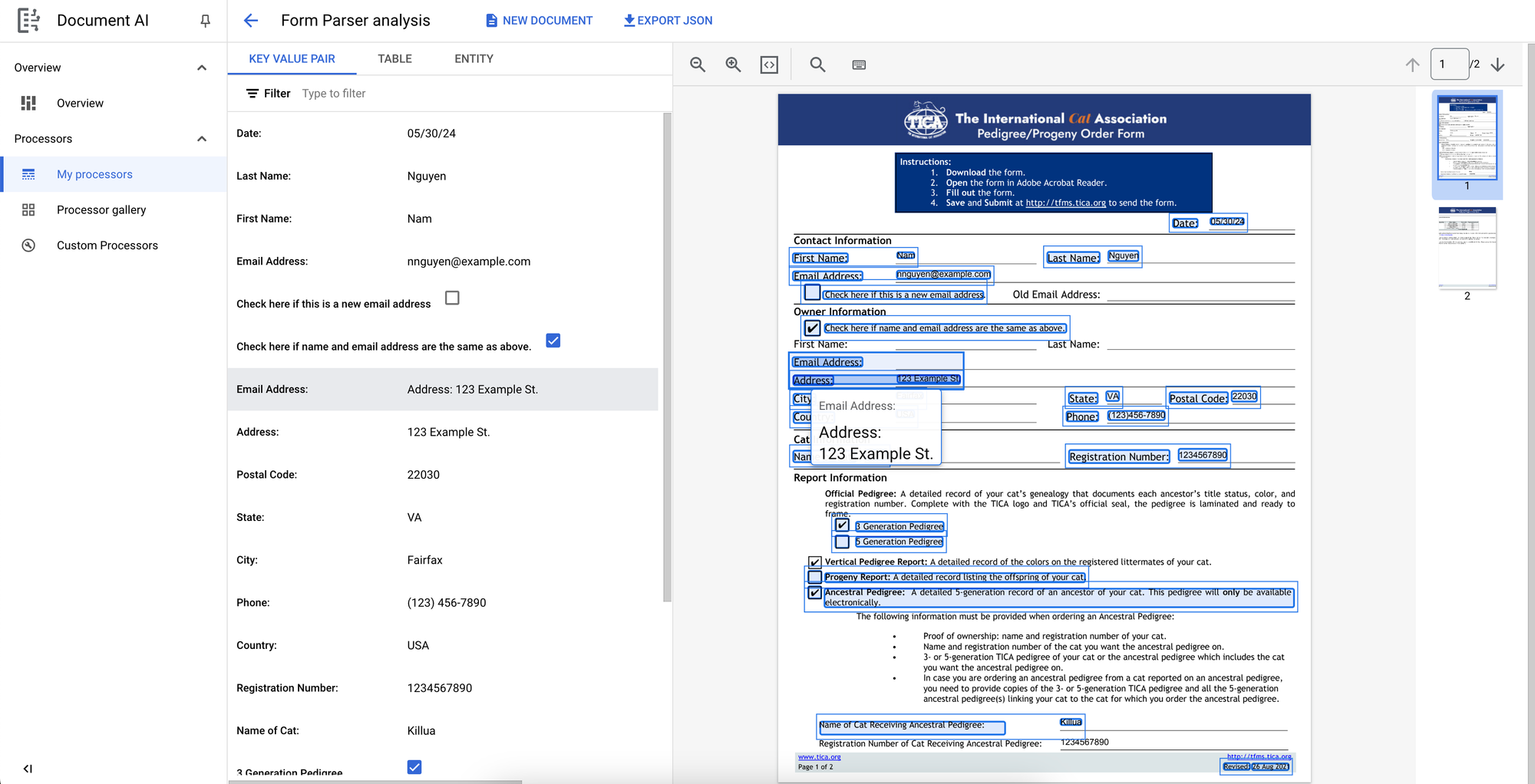
Voila! The parser successfully captured all form keys and values including the checkboxes without any need for training. All of this in, essentially, one click!
How to Use the Custom Extractor
Let’s say there is some extra complexity that the pre-trained processors are not accustomed to. For this case, we’ll walk through training our own Custom Extractor which Document AI provides a clean process to follow.
We’ll start on Document AI’s console at the Custom Processors page.
We’ll follow the same steps as the previous section by clicking CREATE PROCESSOR under Custom Extractor and naming/creating the processor.
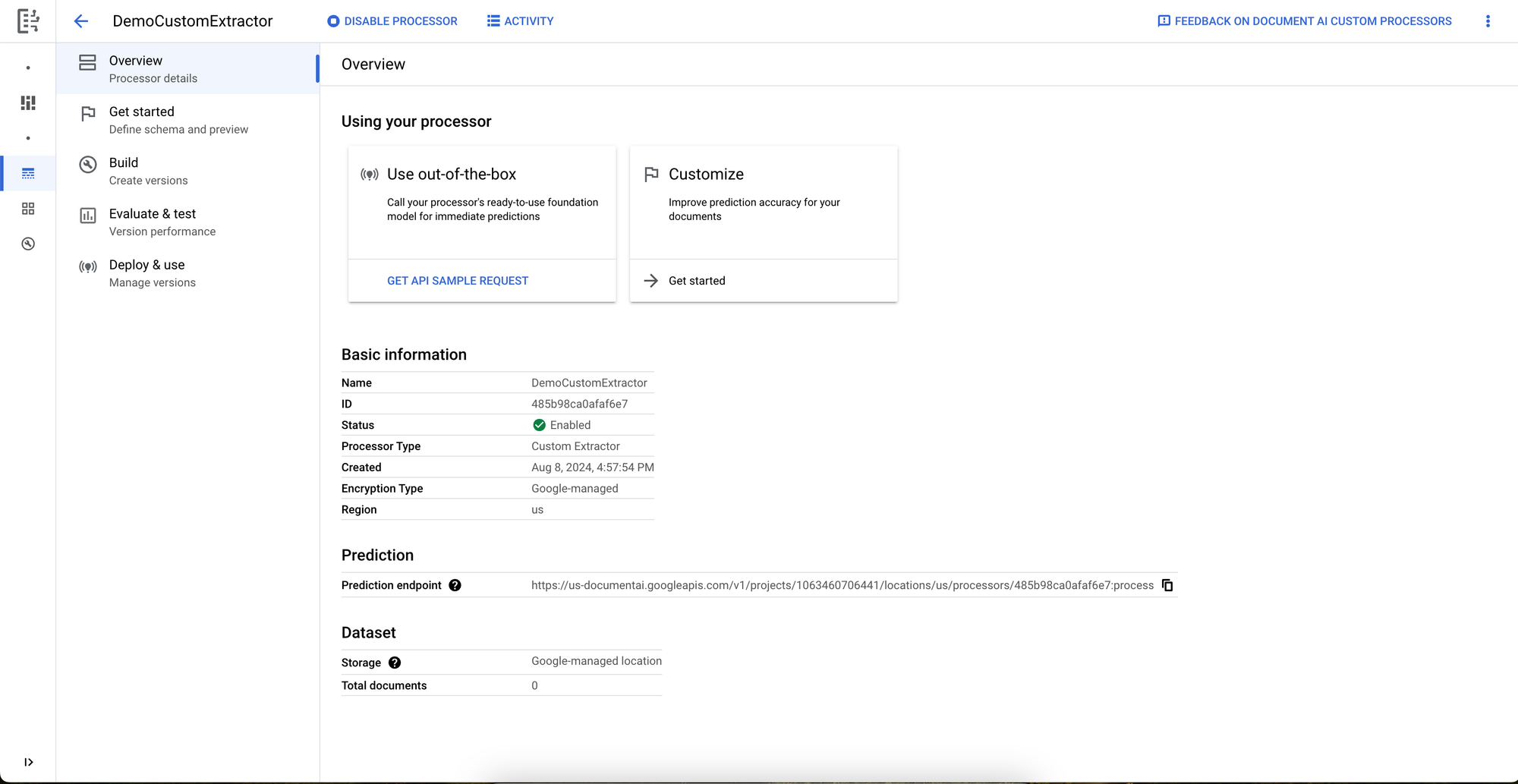
With our DemoCustomExtractor created, the next step is to add and label training data. We’ll click Get Started either in the left panel or under the Customize widget which leads us to the next page to add the fields that we want to extract from our documents.
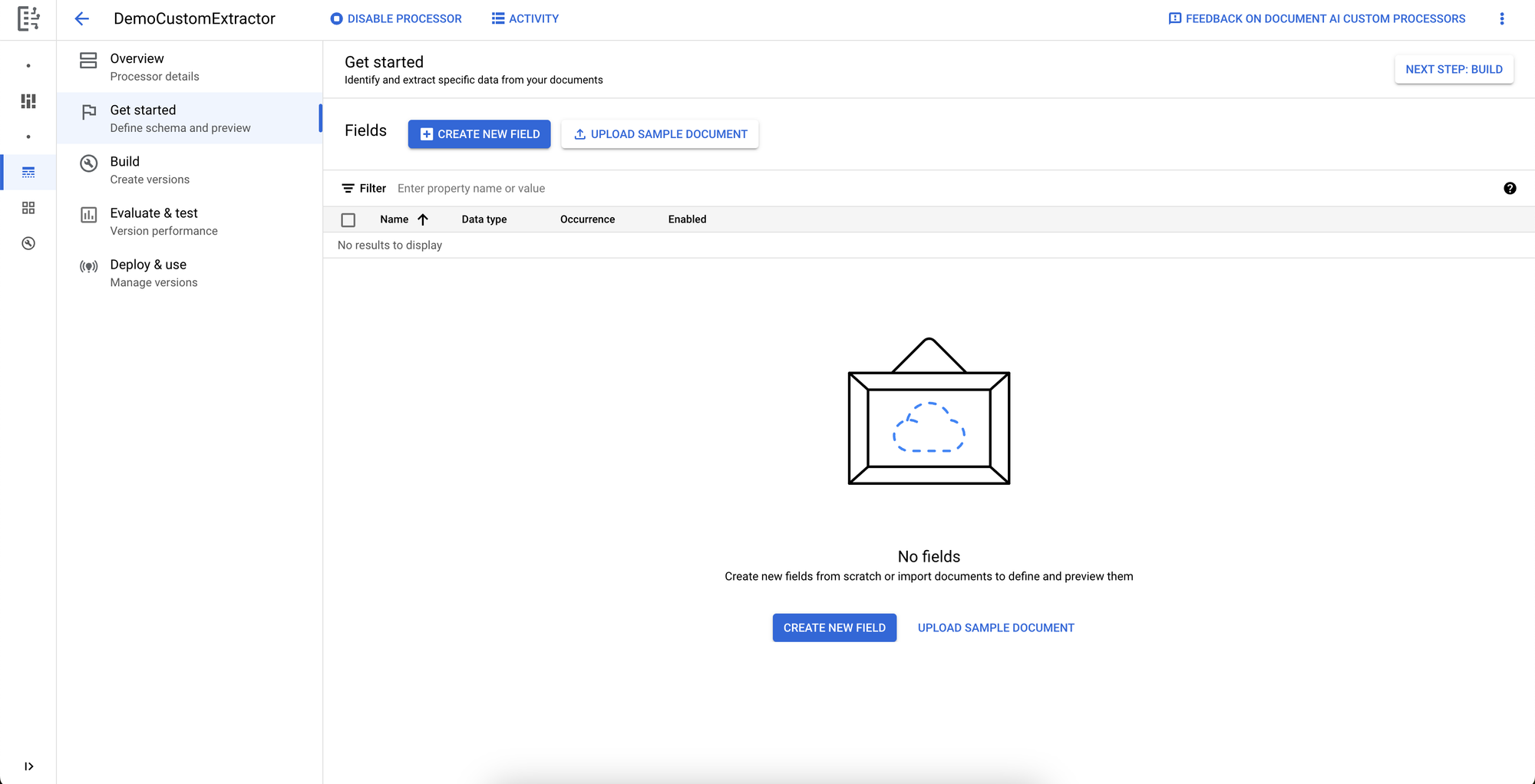
Using the same TICA pedigree form format, we’ll set up the extractor to extract the contact information along with the name and reference number of the cat. We’ll create a new field for each piece we want to extract along with the expected data type of that field and the number of occurrences we expect.
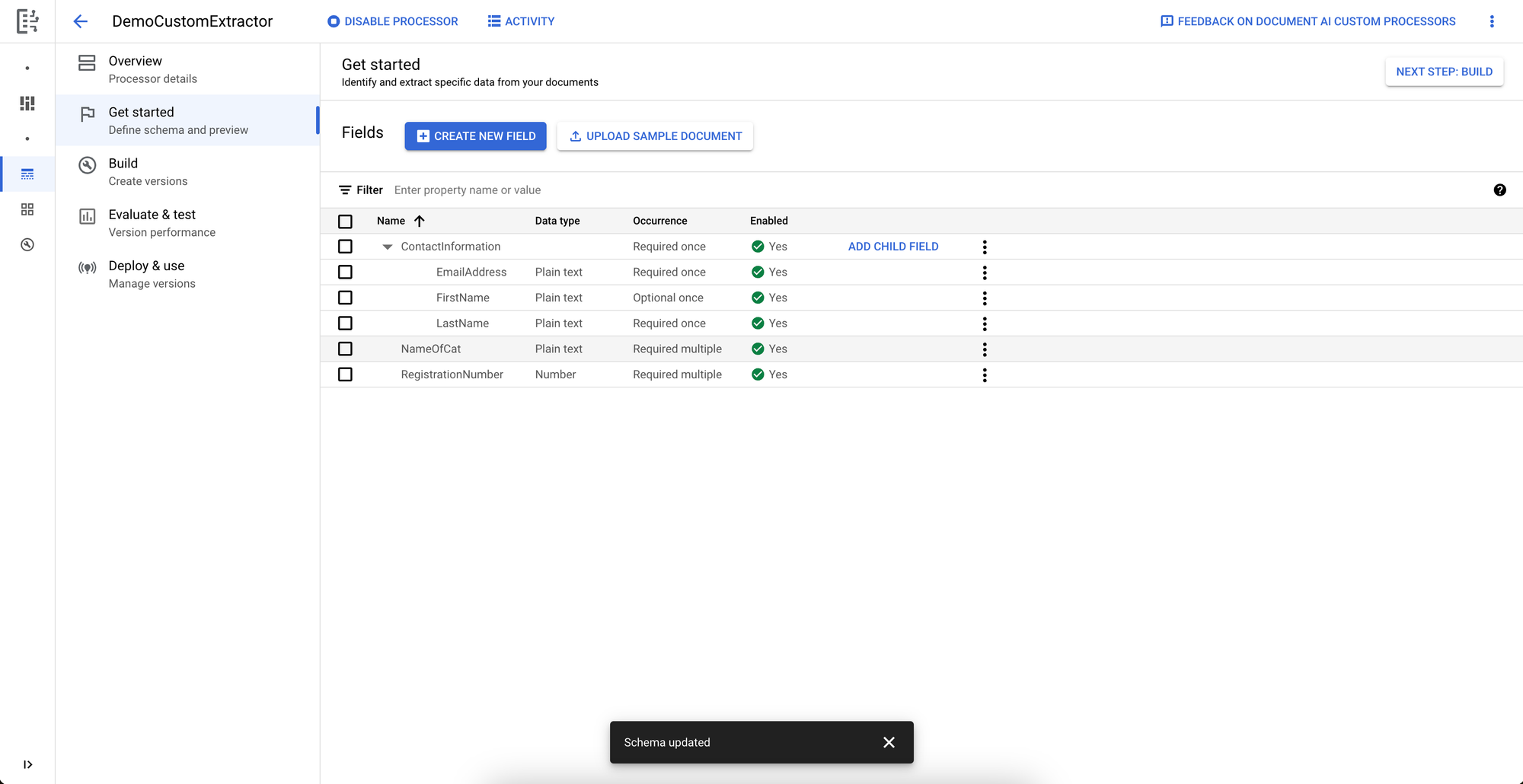
With the fields set up, DocumentAI lets us upload a single sample document to view how the foundational model works with our fields.
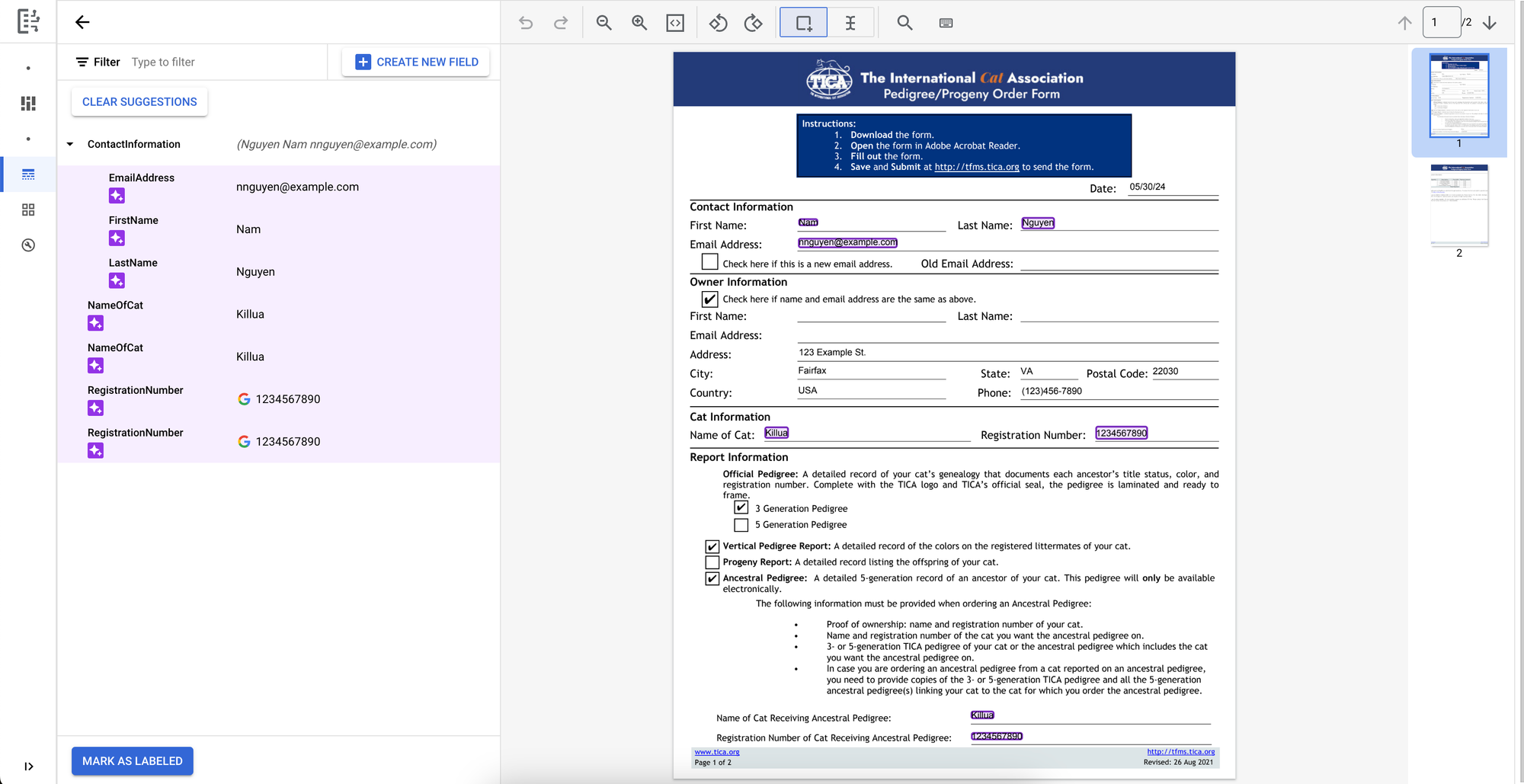
DocumentAI successfully identified our expected fields and added them as suggested labels! We’ll mark this document as labelled with the suggestions and continue to the next “Build” page where we will upload and label the rest of our training/validation dataset.
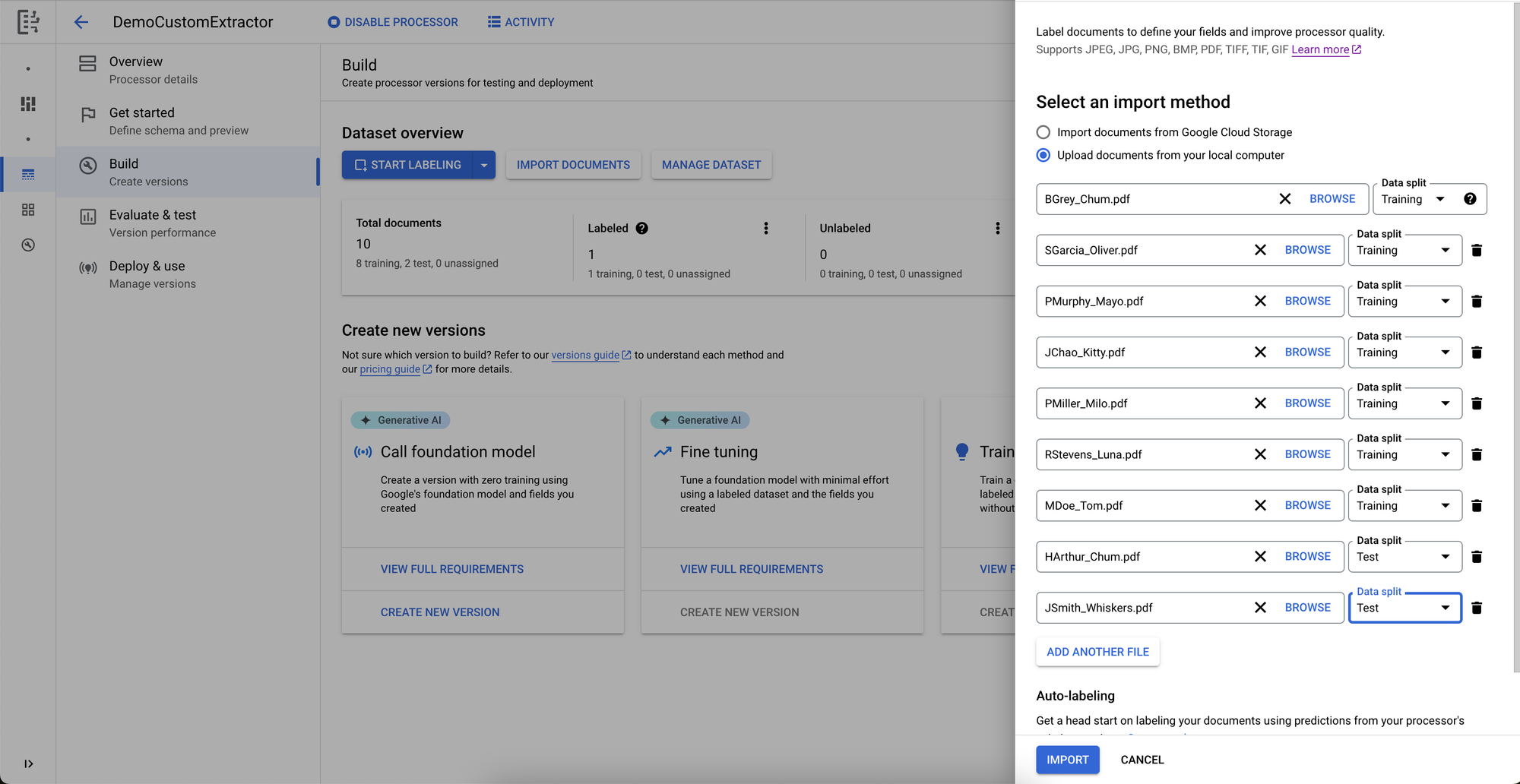
We’ll import an example set of ten documents total and reserve two for validation.
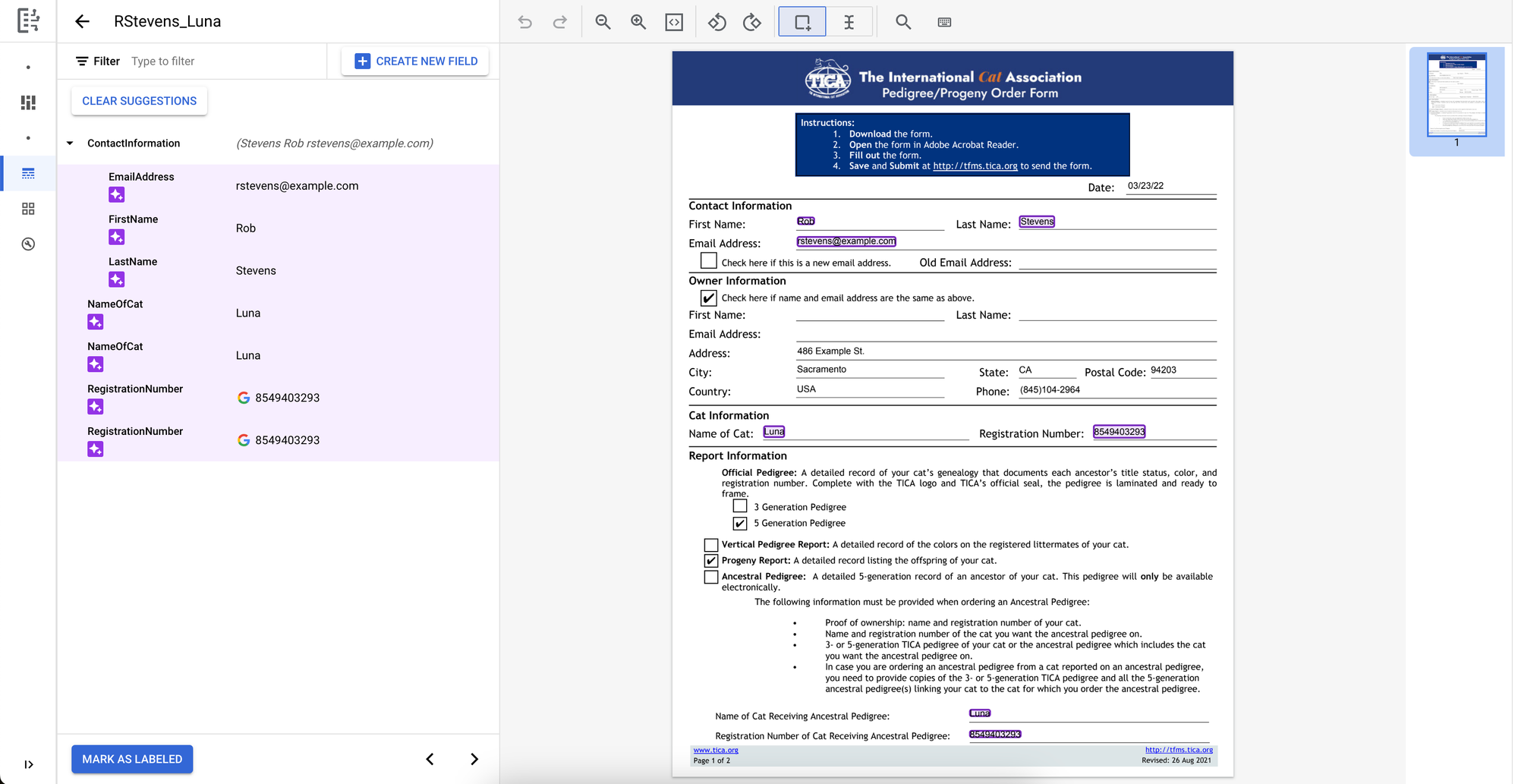
Once the documents have completed uploading, we’ll go through the labelling similar to the view we saw with the initial sample.
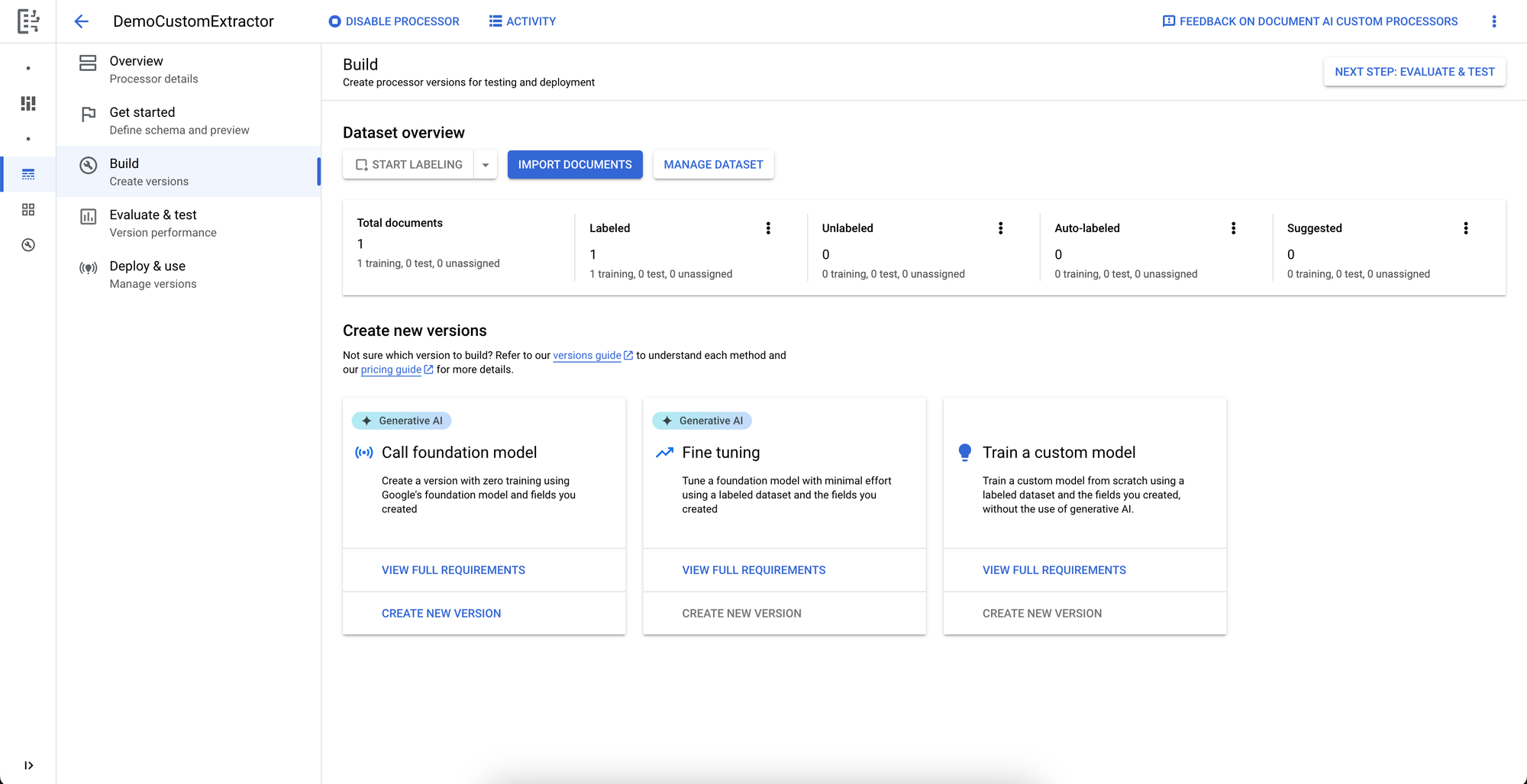
With the dataset now labeled, we’ll click CREATE NEW VERSION under “Call foundation model” on the Build page and name/create the new version. DocumentAI asynchronously builds the new version, and once complete, we can find it listed under the versions in the Evaluate and Test page.
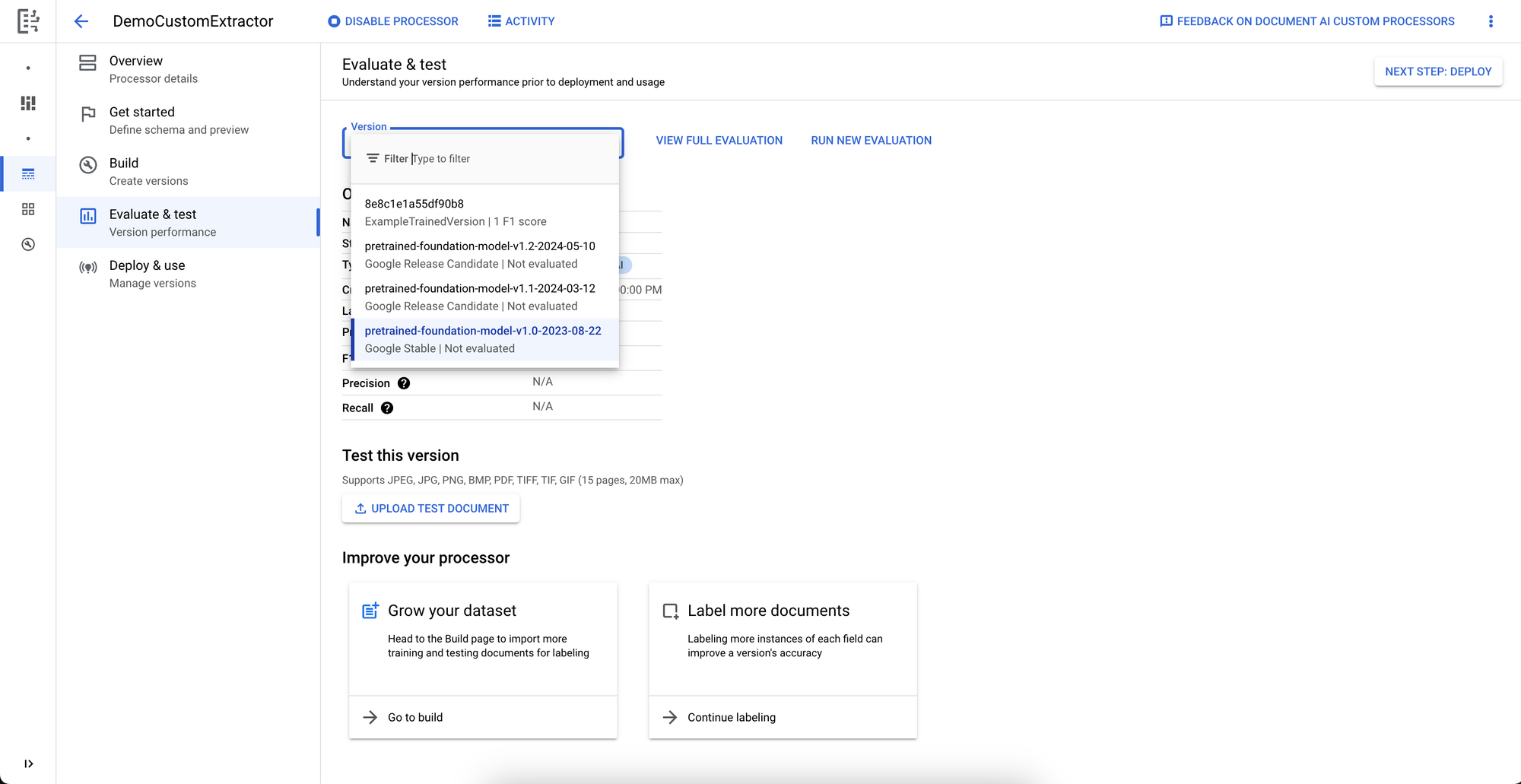
With the files saved for validation, DocumentAI calculates the F1, Precision, and Recall scores during evaluation which you can view by pressing View Full Evaluation with our new version selected. Since I cleanly generating these samples, the scores all show 100% accuracy, but you can expect more variation with more complex documents.
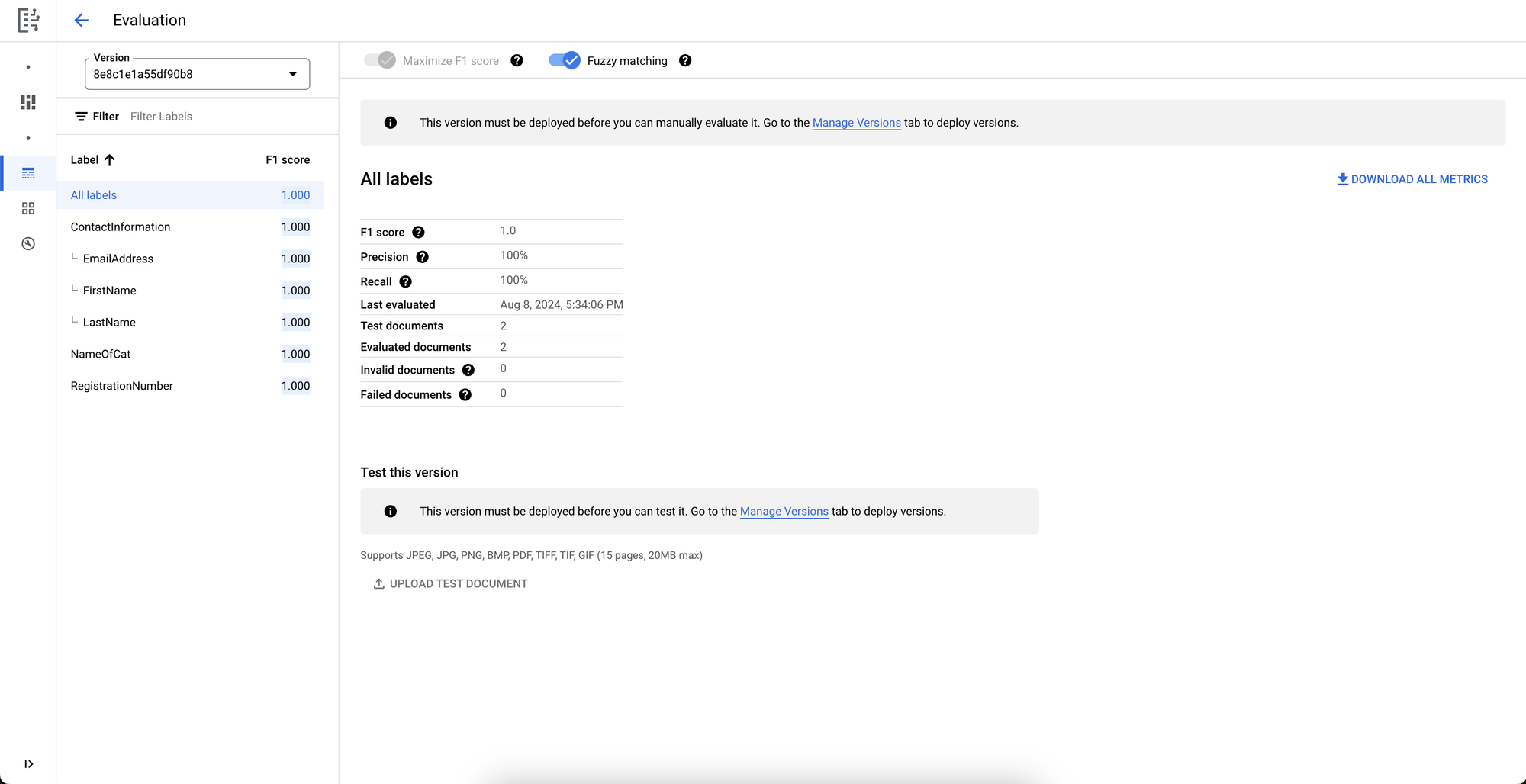
The last step before you can use the new version is to deploy it. We’ll go to the Deploy & Use page where we can select our new version for deployment.
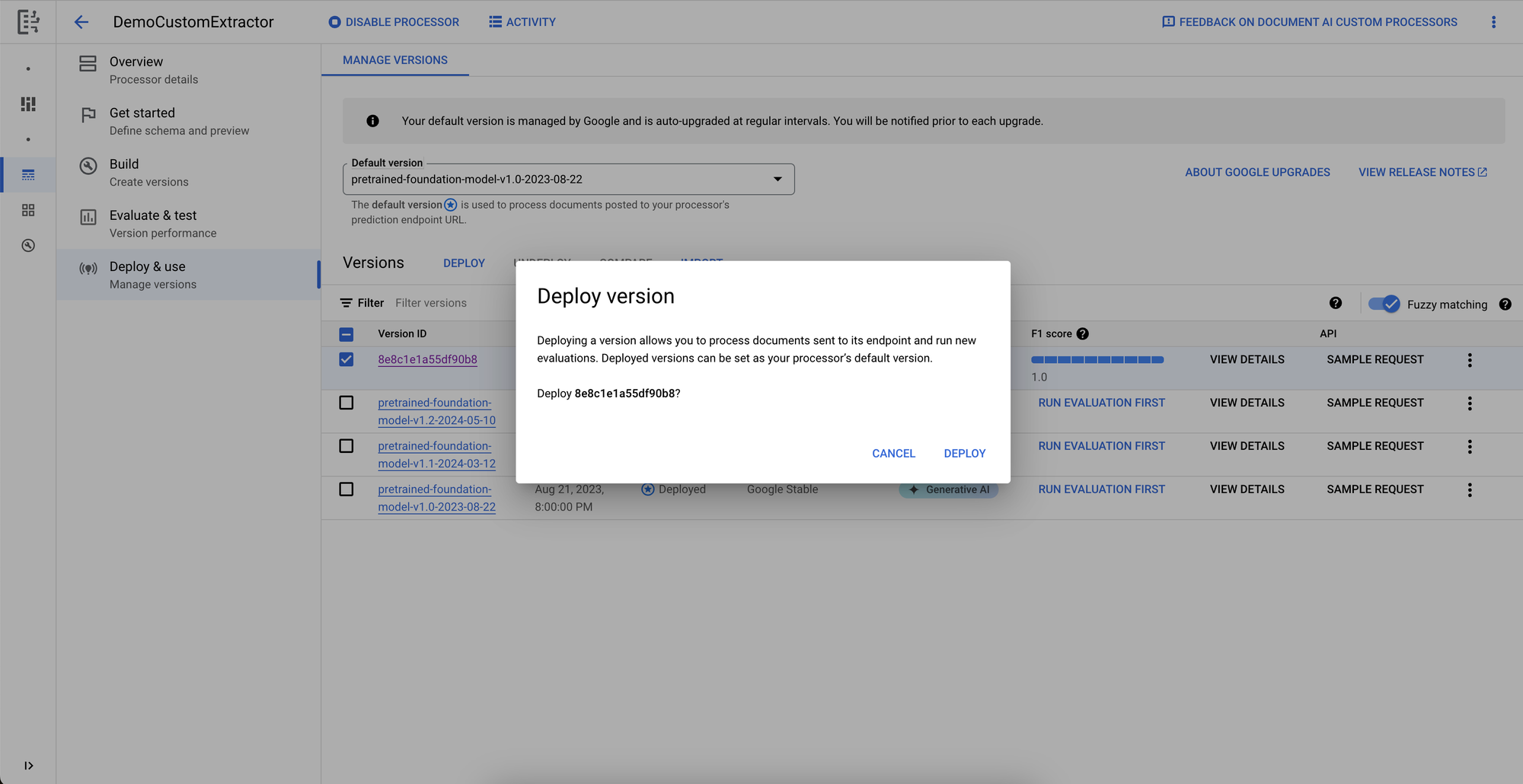
And that’s it! We have a custom extractor now set up to extract the fields that we set.
Conclusion
For our client’s use case, SZNS ended up training and implementing a custom extractor due to variation in the types of documents that we had to process, but the form parser was still close to meeting the bar. My previous experience developing ML models required us to collect and sanitize thousands of samples then loop through training and validation until we had a usable model. With DocumentAI, it is refreshing to discover just how much quicker and simpler the platform allows us to test and implement a solution.
My team at SZNS is always looking for new ways to apply our expertise to help others. If you have something that you need help with, feel free to contact us!
References
Additional references to get started with Document AI

Google Document AI Announcement Blog Post
Document AI Full List of Processors
Document AI Form Parser
Document AI Custom Extractor


